FAQ
Linkis1.0 common problems and solutions: https://docs.qq.com/doc/DWlN4emlJeEJxWlR0
1. Use problems
Q1: The ps-cs service log of linkis reports this error: figServletWebServerApplicationContext (559)
[refresh] - Exception encountered during context initi
alization - cancelling refresh attempt: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'eurekaInstanceLabelClient': Invocation of initkaba method failed; nested exception is java.lang.RuntimeException: com.netflix.client.ClientException: Load balancer does not have available server for client: linkis-ps-publicservice
A: This is because the publicservice service did not start successfully. It is recommended to manually restart the publicservice sh/sbin/linkis-dameo.sh restart ps-publicservice
Q2: Linkis-eureka debugging instructions
A: If you need to debug the eureka program, you need to do some configuration first, as shown below
application-eureka.yml needs to remove part of the comment configuration, and the normal startup configuration is as follows:
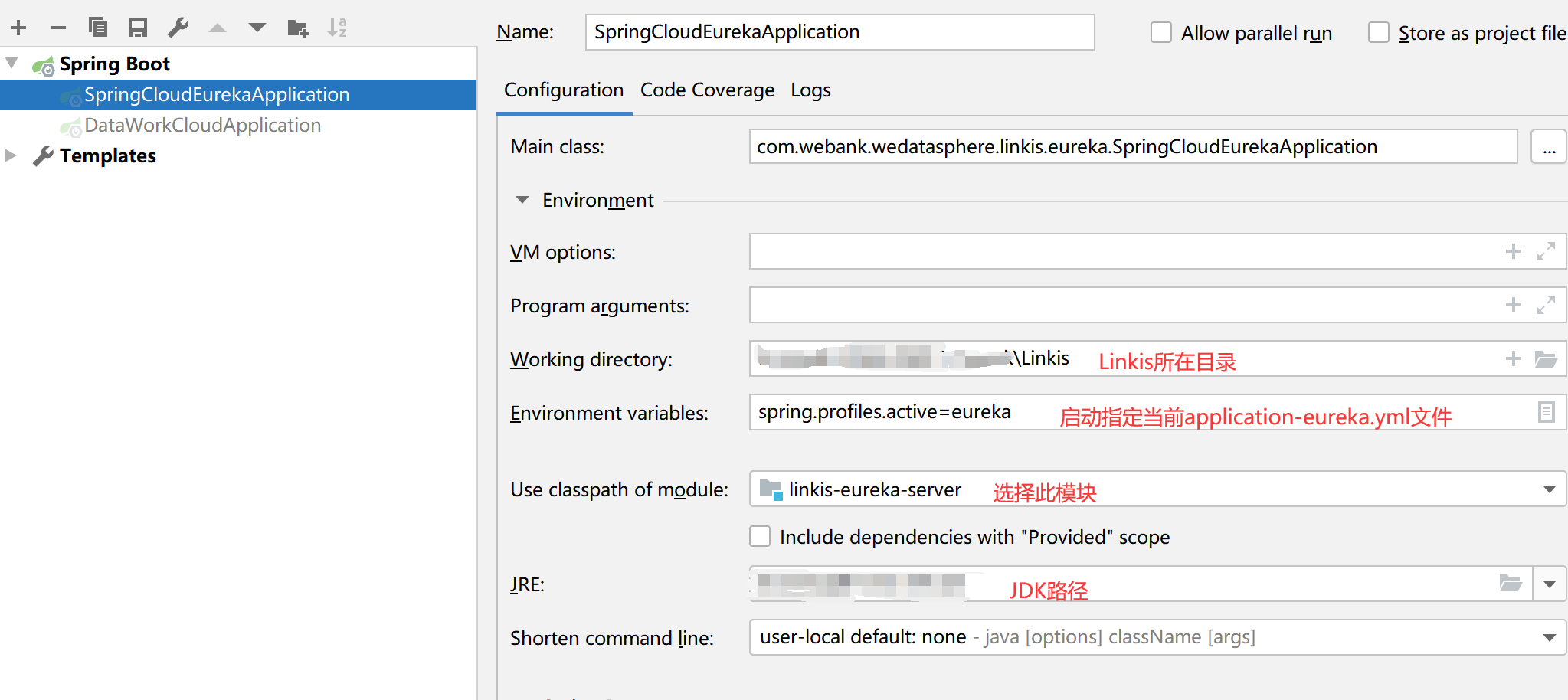
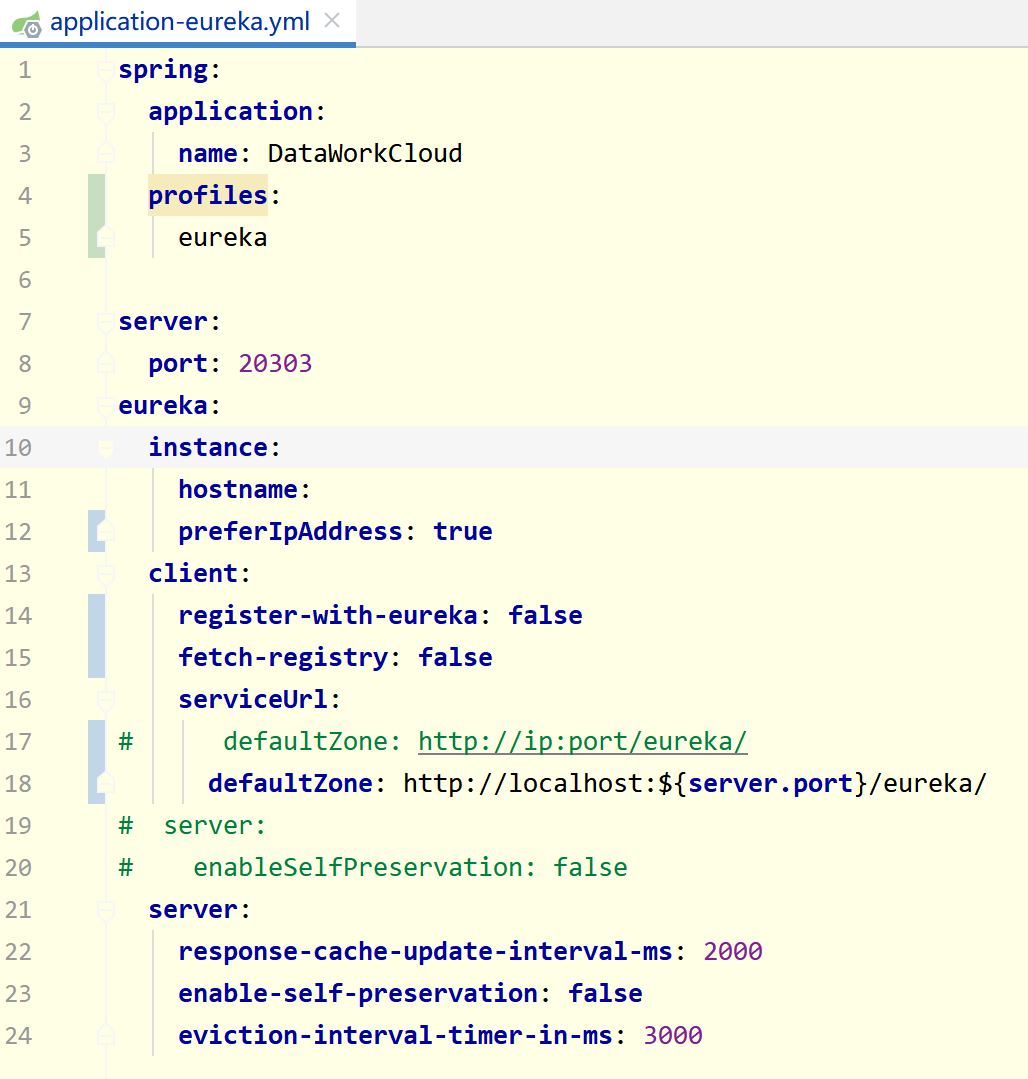
Q3: eureka automatically stops when it starts for the first time, and needs to be restarted manually
A: This is because eureka does not use nohup when starting the Java process. After the session exits, the task is automatically cleaned up by the operating system. You need to modify the eureka startup script and add nohup:

You can refer to PR: https://github.com/apache/linkis/pull/837/files
Q4: Linkis Entrance LogWriter missing dependencies
A: Hadoop 3 needs to modify the linkis-hadoop-common pom file, see: https://linkis.apache.org/zh-CN/docs/next/development/linkis-compile-and-package/
Q5: When Linkis1.0 executes tasks, the ECP service throws the following error: Caused by: java.util.NoSuchElementException: None.get?
Error detailed log:
Solution: At this time, because the corresponding engine version material does not have a corresponding record in the database table, it may be caused by an error when the ecp service is started. You can restart the ecp service to see if there is an error when uploading the BML. The corresponding table is: linkis_cg_engine_conn_plugin_bml_resources
Q6: Linkis1.X general troubleshooting method for insufficient resources
Insufficient resources fall into two situations:
- Insufficient resources of the server itself
- The user's own resources are insufficient (linkis will control user resources). These two resources are recorded in linkis_cg_manager_label_resource and linkis_cg_manager_linkis_resource in linkis1.X, the former is the association table of label and resource, and the latter is the resource table Normally, linkis1.0 is safe for high concurrency control of resources, and it is not recommended to forcibly reset user resource records by modifying table records. However, due to the difference in the execution environment of linkis during the installation and debugging process, engine startup failures may occur, or repeated restarts of microservices during the engine startup process lead to unsafe release of resources, or the monitor does not have time to automatically clean up (some hours) level delay), there may be a problem of insufficient resources, and in severe cases, most of the user's resources will be locked. Therefore, you can refer to the following steps to troubleshoot insufficient resources: a. Confirm on the management console whether the remaining resources of the ECM are greater than the requested resources of the engine. If the remaining resources of the ECM are very small, it will cause the request for a new engine to fail. You need to manually turn off some idle engines in the ECM. There is also a mechanism for automatic release when idle, but this time is set relatively long by default. b. If the ECM resources are sufficient, it must be that the remaining resources of the user are not enough to request a new engine. First, determine the label generated when the user executes the task. For example, if the user hadoop executes the spark2.4.3 script on Scriptis, it will be corresponding in the linkis_cg_manager_label table next record We get the id value of this label, find the corresponding resourceId in the association table linkis_cg_manager_label_resource, and find the corresponding resource record of the label in linkis_cg_manager_linkis_resource through resourceId, you can check the remaining resources in this record
If this resource is checked and determined to be abnormal, that is, it does not match the resources generated by the actual engine startup. The following operations can be performed to recover: After confirming that all engines under the label have been shut down, you can directly delete this resource and the associated record corresponding to the association table linkis_cg_manager_label_resource, and this resource will be automatically reset when you request again. Note: All engines of this label have been shut down. In the previous example, it means that the spark2.4.3 engines started by the hadoop user on Scriptis have all been shut down. You can see all the engines started by the user in the resource management of the management console. instance. Otherwise, the resource record exception of the label may also occur.
Q7: linkis startup error: NoSuchMethodErrorgetSessionManager()Lorg/eclipse/jetty/server/SessionManager
Specific stack:
startup of context o.s.b.w.e.j.JettyEmbeddedWebAppContext@6c6919ff{application,/,[file:///tmp/jetty-docbase.9102.6375358926927953589/],UNAVAILABLE} java.lang.NoSuchMethodError: org.eclipse.jetty.server.session.SessionHandler.getSessionManager()Lorg/eclipse/jetty/server/SessionManager;
at org.eclipse.jetty.servlet.ServletContextHandler\$Context.getSessionCookieConfig(ServletContextHandler.java:1415) ~[jetty-servlet-9.3.20.v20170531.jar:9.3.20.v20170531]
Solution: jetty-servlet and jetty-security versions need to be upgraded from 9.3.20 to 9.4.20;
2. Environmental issues
Q1: Linkis1.0 execution task report: select list is not in group by clause
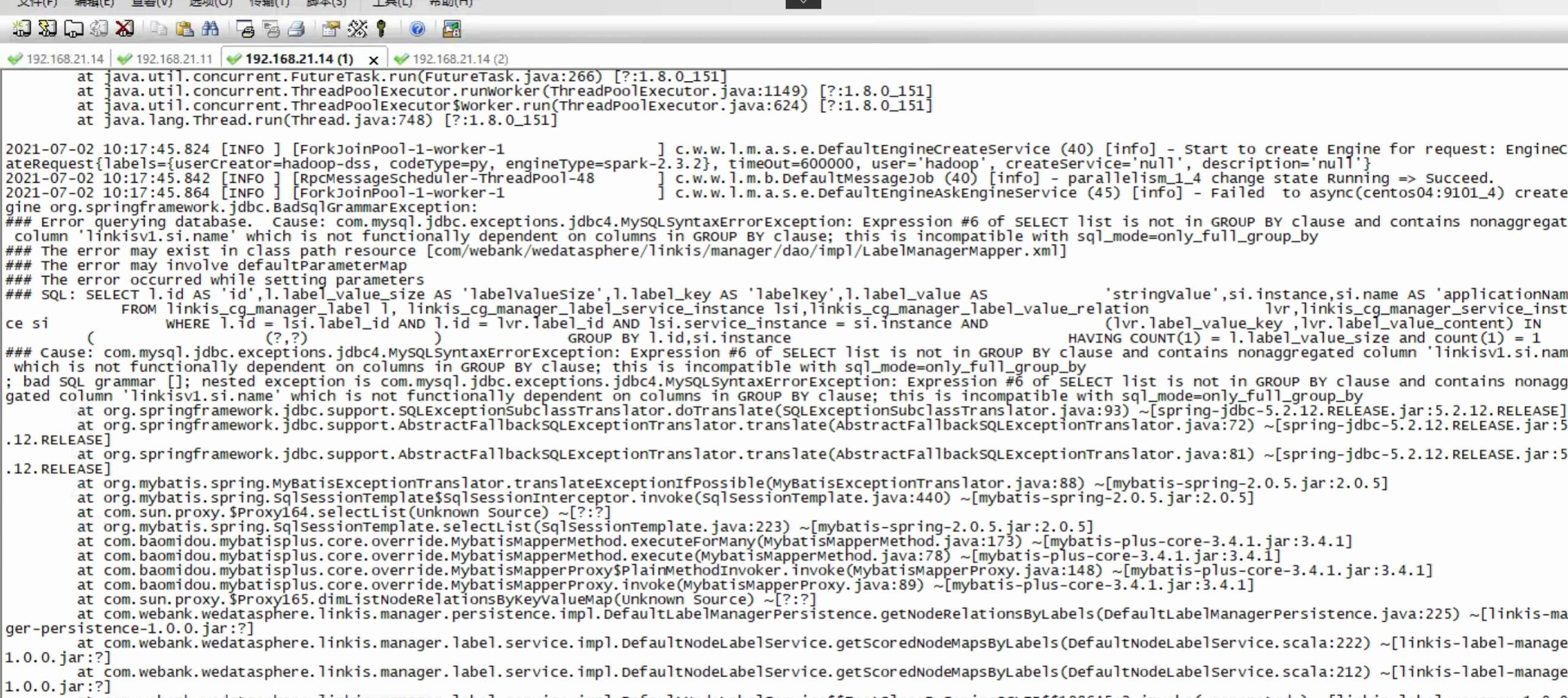
This problem is caused by the default value of the global setting mode in mysql 5.8 version, you need to execute the following line in the mysql cli:
SET GLOBAL sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
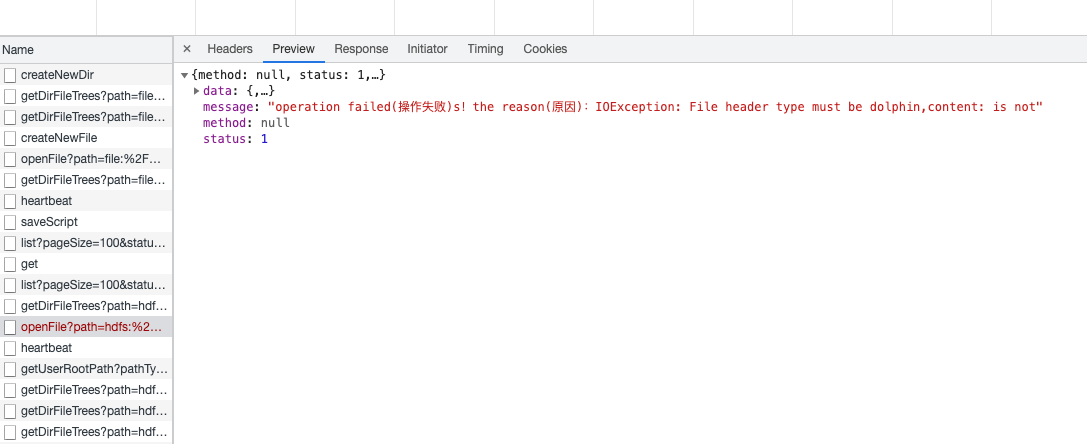
Q2: When executing scripts after deployment, executing commands, and collecting results, I encountered such an error, IOException: File header type must be dolphin:
A: This should be caused by repeated installations, resulting in the result set being written in the same file. The previous Linkis 0.X version used the result set to write append, and 1.0 has been modified to add a new one. You can clean up the result set Directory: The configuration parameter is wds.linkis.resultSet.store.path, you can clean up this directory
Q3: The json4s package conflict caused by inconsistent Spark versions, the error is as follows: Error message: caused by: java.lang.NoSuchMethodError: org.json4s.jackson.jsonMethod$
solution: This is because of Spark jars' json4s and lib/linkis-engineconn-plugins/spark/dist/version/lib The json4s version in the package is inconsistent. When the official release is released, the supported version of Spark will be indicated later. If it is inconsistent, this problem will exist. The solution is to replace the json4s package in Spark jars with lib/linkis-engineconn-plugins/spark/dist/version/lib The json4s version inside the package. In addition, there may be conflicts in the netty package, which can be handled according to the method of Json4s. Then restart the ecp service: sh sbin/linkis-damon.sh restart cg-engineplugin
Q4: When Linkis1.X submits spark sql tasks in version CDH5.16.1, how to troubleshoot 404 problems
The main error message is as follows:
21304, Task is Failed,errorMsg: errCode: 12003 ,desc: ip:port_x Failed to async get EngineNode FeignException.NotFound: status 404 reading RPCReceiveRemote#receiveAndReply(Message) ,ip: xxxxx ,port: 9104 ,serviceKind: linkis-cg-entrance
org.apache.jasper.servlet.JspServlet 89 warn - PWC6117: File "/home/hadoop/dss1.0/tmp/hadoop/workDir/7c3b796f-aadd-46a5-b515-0779e523561a/tmp/jetty-docbase.1802511762054502345.46019/api/rest_j/v1/rpc/receiveAndReply" not found
The above error message is mainly caused by the jar conflict in the cdh environment variable. You need to find the jar package where the org.apache.jasper.servlet.JspServlet class is located. The local cdh environment variable path is: /opt/cloudera/parcels/CDH -5.16.1-1.cdh5.16.1.p0.3/jars, delete the corresponding jasper-compile-${version}.jar and jsp-${version}.jar jar packages under this directory, The spark sql task can be run again without restarting the service, and the problem is solved.
Q5: running error report missing package matplotlib
In the standard python environment, anaconda2 and anaconda3 need to be installed, and the default anaconda is anaconda2. This contains most common python libraries.
Q6: When the microservice linkis-ps-cs is started, DebuggClassWriter overrides final method visit is reported
Specific exception stack:
Solution: jar package conflict, delete asm-5.0.4.jar;
Q7: When the shell engine schedules execution, the engine execution directory reports the following error /bin/java: No such file or directory:

Solution: There is a problem with the environment variables of the local java, and a symbolic link needs to be made to the java command.
Q8: When the hive engine is scheduled, the error log of engineConnManager is as follows: method did not exist: SessionHandler:

Solution: Under the hive engine lib, the jetty jar package conflicts, replace jetty-security and jetty-server with 9.4.20;
Q9: When the hive engine is executing, the following error is reported Lcom/google/common/collect/UnmodifiableIterator:
2021-03-16 13:32:23.304 ERROR [pool-2-thread-1]com.webank.wedatasphere.linkis.engineplugin.hive.executor.HiveEngineConnExecutor 140 run - query failed, reason : java.lang.AccessError: tried to access method com.google.common.collect.Iterators.emptyIterator() Lcom/google/common/collect/UnmodifiableIterator; from class org.apache.hadoop.hive.ql.exec.FetchOperator
at org.apache.hadoop.hive.ql.exec.FetchOperator.<init>(FetchOperator.java:108) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.exec.FetchTask.initialize(FetchTask.java:86) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql..compile(Driver.java:629) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1414) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1543) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1332) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1321) ~[hive-exec-2.1.1-cdh6.1.0.jar:2.1.1-cdh6.1.0]
atcom.webank.wedatasphere.linkis.engineplugin.hive.executor.HiveEngineConnExecutor$$anon$1.run(HiveEngineConnExecutor.scala:152) [linkis-engineplugin-hive-dev-1.0.0.jar:?]
atcom.webank.wedatasphere.linkis.engineplugin.hive.executor.HiveEngineConnExecutor$$anon$1.run(HiveEngineConnExecutor.scala:126) [linkis-engineplugin-hive-dev-1.0.0.jar:?]
Solution: guava package conflict, delete guava-25.1-jre.jar under hive/dist/v1.2.1/lib;
Q10: During engine scheduling, the following error is reported: Python processes is not alive:

Solution: Install the anaconda3 package manager on the server. After debugging python, two problems were found: (1) lack of pandas and matplotlib modules, which need to be installed manually; (2) when the new version of the python engine is executed, it depends on a higher version of python, and python3 is installed first. Next, make a symbolic link (as shown below), and restart the engineplugin service.
Q11: When the spark engine is running, the following error is reported: NoClassDefFoundError: org/apache/hadoop/hive/ql/io/orc/OrcFile:
2021-03-19 15:12:49.227 INFO [dag-scheduler-event-loop] org.apache.spark.scheduler.DAGScheduler 57 logInfo -ShuffleMapStage 5 (show at <console>:69) failed in 21.269 s due to Job aborted due to stage failure: Task 1 in stage 5.0 failed 4 times, most recent failure: Lost task 1.3 in stage 5.0 (TID 139, cdh03, executor 6):java.lang.NoClassDefFoundError: org/apache/hadoop/hive/ql/io/orc/OrcFile
Solution: The classpath of the cdh6.3.2 cluster spark engine only has /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/jars, you need to add hive-exec-2.1.1- cdh6.1.0.jar, and restart spark.
Three, configuration problems
Q1: The database on the left side of the script cannot be refreshed
solution: a. The reason may be that the linkis-metatdata service did not read the HIVE_CONF_DIR error, you can configure the parameters of linkis-metadata: corresponding to the JDBC connection string of the metadata database
hive.meta.url=
hive.meta.user=
hive.meta.password=
Q2: The right side of Scriptis cannot refresh the database, and it has been refreshing (it should be noted that the metadata of linkis does not support docking sentry and Ranger for the time being, only supports native permission control of hive), error message: the front-end database tab has been refreshing state
solution: This is because we have restricted permissions for the database on the right, and this relies on hive to enable authorized access:
hive.security.authorization.enabled=true;
For details, please refer to: https://blog.csdn.net/yancychas/article/details/84202400 If you have configured this parameter and have not yet enabled it, you need to grant the user the corresponding database table permission and execute the grant statement. You can refer to the same link authorization section.
# Authorization reference Take hadoop as an example:
# Enter the hive client to check the hadoop user database authorization status:
show grant user hadoop on database default;
# Authorize the user database:
grant all on database default to user hadoop;
If you don't want to enable permission control, that is, every user can see the library table, you can modify: com/webank/wedatasphere/linkis/metadata/hive/dao/impl/HiveMetaDao.xml sql remove the permission control part
Q3: [Scriptis][Workspace] When I log in to Scriptis, the root directory does not exist, and there are two root directories: workspace and HDFS: Error message: After logging in, the front end pops up the following message (the user’s local directory does not exist, please Contact admin to add)
solution:
- a. Confirm the linkis.properties parameter in the conf directory of linkis-ps-publicservice: wds.linkis.workspace.filesystem.localuserrootpath=file:///tmp/linkis/ Does it start with file://?
- b. Confirm whether wds.linkis.workspace.filesystem.hdfsuserrootpath.prefix=hdfs:///tmp/linkis/ starts with hdfs://
- c. Confirm whether there is a user directory under the /tmp/linkis directory. The user here refers to the front-end login user, such as hadoop user login, then create: /tmp/linkis/hadoop directory, if the directory exists, confirm the directory permission login user It can be operated. If it still doesn’t work, you can refer to the error report of publicservice. The error will explain the permission or the path problem.
Q4: [Management Console][Settings] How to adjust the yarn queue used by the task? Error message: When executing the sql task, it is reported that 1. Obtaining the Yarn queue information is abnormal or user XX cannot submit to the queue
solution: In the front end - management console - settings - general settings - Yarn queue configuration login user has permission queue
Q5: When Hive queries, it reports: Can not find zk-related classes such as: org.apache.curator., error message: When executing hive tasks, the log report cannot find the class starting with org.apache.curator. , classNotFound
solution: This is because the hive transaction is enabled, you can modify the hive-site.xml on the linkis machine to turn off the transaction configuration, refer to the hive transaction: https://www.jianshu.com/p/aa0f0fdd234c Or put the relevant package into the engine plugin directory lib/linkis-engineconn-plugins/hive/dist/version/lib
Q6: How does Linkis support kerberos
solution: Obtaining Hadoop's FileSystem in linkis is implemented through the HDFSUtils class, so we put kerberos in this class, and users can see the logic of this class. The login modes currently supported are as follows:
if(KERBEROS_ENABLE.getValue) {
val path = new File(
TAB_FILE.getValue , userName + ".keytab").getPath
val user = getKerberosUser(userName)
UserGroupInformation.setConfiguration(getConfiguration(userName))
UserGroupInformation.loginUserFromKeytabAndReturnUGI(user, path)
} else {
UserGroupInformation.createRemoteUser(userName)
}
Users only need to configure the following parameters in the configuration file linkis.properties:
wds.linkis.keytab.enable=true
wds.linkis.keytab.file=/appcom/keytab/ #keytab placement directory, which stores the username.keytab files of multiple users
wds.linkis.keytab.host.enabled=false #Whether to bring principle client authentication
wds.linkis.keytab.host=127.0.0.1 #principle authentication needs to bring the client IP
Q7: Regarding Linkis, besides supporting deployment user login, can other user logins be configured?
solution: sure. Deployment users are for convenience only. linkis-mg-gateway supports access by configuring LDAP service and SSO service. It does not have a user verification system. For example, to enable LDAP service access, you only need to configure linkis-mg-gateway.properties. The configuration of your LDAP server is as follows:
wds.linkis.ldap.proxy.url=ldap://127.0.0.1:1389/#Your LDAP service URL
wds.linkis.ldap.proxy.baseDN=dc=webank,dc=com#Configuration of your LDAP service
If the user needs to perform tasks, a user with the corresponding user name needs to be created on the Linux server. If it is a standard version, the user needs to be able to perform Spark and hive tasks, and needs to establish a corresponding user in the local workspace and HDFS directory /tmp/linkis directory.
Q8: How to open Linkis management console, administrator page ECM and microservice management?

Solution: You need to set the administrator in the conf/linkis.properties file:
wds.linkis.governance.station.admin=hadoop,peacewong
After the setting is complete, restart the publicservice service
Q9: When starting the microservice linkis-ps-publicservice, kJdbcUtils.getDriverClassName NPE
Specific exception stack: ExternalResourceProvider

Solution: Caused by linkis-ps-publicservice configuration problem, modify the three parameters at the beginning of linkis.properties hive.meta:
Q10: When scheduling the hive engine, the following error is reported: EngineConnPluginNotFoundException: errorCode: 70063

Solution: The version of the corresponding engine was not modified during installation, so the engine type inserted into the db by default is the default version, and the compiled version is not the default version.
Specific modification steps:
cd /appcom/Install/dss-linkis/linkis/lib/linkis-engineconn-plugins/,
Modify the v2.1.1 directory name in the dist directory to v1.2.1
Modify the subdirectory name 2.1.1 under the plugin directory to the default version 1.2.1
If it is Spark, you need to modify dist/2.4.3 and plugin/2.4.3 accordingly
Finally restart the engineplugin service.
Q11: When the hive engine schedules execution, the following error is reported: opertion failed NullPointerException:

Solution: The server lacks environment variables, and /etc/profile adds export HIVE_CONF_DIR=/etc/hive/conf;
Q12: When the spark engine starts, an error is reported get the queue information excepiton. (obtaining Yarn queue information exception) and http link exception
Solution: To migrate the address configuration of yarn to the DB configuration, the following configuration needs to be added:
INSERT INTO `linkis_cg_rm_external_resource_provider` (`resource_type`, `name`, `labels`, `config`) VALUES ('Yarn', 'default', NULL, '{\r\n"rmWebAddress": "http://xxip:xxport",\r\n"hadoopVersion": "2.7.2",\r\n"authorEnable":true,\r\n"user":"hadoop",\r\n"pwd":"xxxx"\r\n}');
config field example
{
"rmWebAddress": "http://10.10.10.10:8080",
"hadoopVersion": "2.7.2",
"authorEnable":true,
"user":"hadoop",
"pwd":"passwordxxx"
}

Q13: pythonspark scheduling execution, error: initialize python executor failed ClassNotFoundException org.slf4j.impl.StaticLoggerBinder
details as follows:

Solution: The reason is that the spark server lacks slf4j-log4j12-1.7.25.jar, copy the above jar to /opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark/jars .
Q14: Common package conflicts:
java.lang.NoSuchMethodError: javax.ws.rs.core.Application.getProperties()Ljava/util/Map; The conflict package is: jsr311-api-1.1.1.jar may also conflict with jessery
java.lang.BootstrapMethodError: java.lang.NoSuchMethodError: javax.servlet.ServletContext.setInitParameter(Ljava/lang/String;Ljava/lang/String;)Z
The conflict package is: servlet-api.jar
org/eclipse/jetty/util/processorUtils The conflicting package is: jetty-util-9.4.11.v20180605.jar This is the correct version
java.lang.NoClassDefFoundError: Could not initialize class dispatch.Http$
The conflicting package needs to be copied in: netty-3.6.2.Final.jar
Conflicts caused by other jars brought in by hive-exec Calcite-avatica-1.6.0.jar may also bring conflicts in the jackson package, resulting in errors related to com.fasterxml.jackson.databind Cannot inherit from final class is caused by calcite-avatica-1.6.0.jar
LZO compression problem hadoop-lzo jar 7.org.eclipse.jetty.server.session.SessionHandler.getSessionManager()Lorg/eclipse/jetty/server/SessionManager; Need to replace conflicting packages: jetty-servlet and jetty-security with 9.4.20
Q15: The Mysql script running Scripts reports an error\sql engine reports an error
MYSQL script: run sql error:
com.webank.wedatasphere.linkis.orchestrator.ecm.exception.ECMPluginErrorException: errCode: 12003 ,desc: localhost:9101_0 Failed to async get EngineNode RMErrorException: errCode: 11006 ,desc: Failed to request external resourceClassCastException: org.json4s.JsonAST$JNothing$ cannot be cast to org.json4s.JsonAST$JString ,ip: localhost ,port: 9101 ,serviceKind: linkis-cg-linkismanager ,ip: localhost ,port: 9104 ,serviceKind: linkis-cg-entrance
at com.webank.wedatasphere.linkis.orchestrator.ecm.ComputationEngineConnManager.getEngineNodeAskManager(ComputationEngineConnManager.scala:157) ~[linkis-orchestrator-ecm-plugin-1.0.2.jar:?]
Solution: modify the correct yarn address in the linkis_cg_rm_external_resource_provider table
Q16: The waiting time for scriptis to execute the script is long

scriptis execution script waits for a long time, and reports Failed to async get EngineNode TimeoutException: Solution: You can check the linkismanager log, usually because the engine startup timed out
Q17: scriptis executes jdbc script and reports an error
scriptis executes the jdbc script and reports an error
Failed to async get EngineNode ErrorException: errCode: 0 ,desc: operation failed(操作失败)s!the reason(原因):EngineConnPluginNotFoundException: errCode: 70063 ,desc: No plugin foundjdbc-4please check your configuration
Solution You need to install the corresponding engine plug-in, you can refer to: Engine Installation Guide
Q18: Turn off resource checking
Error reporting phenomenon: Insufficient resources Linkismanager service modify this configuration: wds.linkis.manager.rm.request.enable=false You can clean up resource records, or set smaller resources or turn off detection Linkismanager service modify this configuration: wds.linkis.manager.rm.request.enable=false
Q19: Executing the script reports an error
GatewayErrorException: errCode: 11012 ,desc: Cannot find an instance in the routing chain of serviceId [linkis-cg-entrance], please retry ,ip: localhost ,port: 9001 ,serviceKind: linkis-mg-gateway

A: Please check whether the linkis-cg-entrance service starts normally.
Q20: ScriptIs execute script TimeoutException

In linkis-cg-linkismanager.log, Need a ServiceInstance(linkis-cg-entrance, localhost:9104), but cannot find in DiscoveryClient refresh list is repeatedly printed. This is because the instance is forcibly shut down, but the persistence in the database thinks that the instance still exists. The solution is to clear the two tables linkis_cg_manager_service_instance and linkis_cg_manager_service_instance_metrics after stopping the service.
Q21: Engine timeout setting

① The parameter configuration of the management console can correspond to the engine parameters, and the timeout time can be modified. After saving, kill the existing engine. ②If the timeout configuration is not displayed, you need to manually modify the linkis-engineconn-plugins directory, the corresponding engine plugin directory such as spark/dist/v2.4.3/conf/linkis-engineconn.properties, the default configuration is wds.linkis.engineconn.max.free.time =1h, means 1h overtime, and can have units m and h. 0 means no timeout, no automatic kill. After the change, you need to restart ecp, and kill the existing engine, and run a new task to start the engine to take effect.
Q22: When creating a new workflow, it prompts "504 Gateway Time-out"

Error message: The instance 05f211cb021e:9108 of application linkis-ps-cs is not exists. ,ip: 5d30e4bb2f42 ,port: 9001 ,serviceKind: linkis-mg-gateway, as shown below:
Q23: Scripts execute python scripts (the content of the script is very simple print) and execute successfully normally. It can also be executed successfully through the task scheduling system. It can also be executed successfully through the job flow editing job script page, but an error is reported through job flow execution.
Error message:
You can go to this path(/opt/kepler/work/engine/hadoop/workDir/9c28976e-63ba-4d9d-b85e-b37d84144596/logs) to find the reason or ask the administrator for help ,ip: host1 ,port: 9101 ,serviceKind: linkis-cg-linkismanager ,ip: host1 ,port: 9104 ,serviceKind: linkis-cg-entrance
Exception in thread "main" java.lang.NullPointerException
at com.webank.wedatasphere.linkis.rpc.sender.SpringCloudFeignConfigurationCache$.getClient(SpringCloudFeignConfigurationCache.scala:73)
at com.webank.wedatasphere.linkis.rpc.sender.SpringMVCRPCSender.doBuilder(SpringMVCRPCSender.scala:49)
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=250m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Exception in thread "main" java.lang.NullPointerException
at com.webank.wedatasphere.linkis.rpc.sender.SpringCloudFeignConfigurationCache$.getClient(SpringCloudFeignConfigurationCache.scala:73)
at com.webank.wedatasphere.linkis.rpc.sender.SpringMVCRPCSender.doBuilder(SpringMVCRPCSender.scala:49)
at com.webank.wedatasphere.linkis.rpc.BaseRPCSender.newRPC(BaseRPCSender.scala:67)
at com.webank.wedatasphere.linkis.rpc.BaseRPCSender.com$webank$wedatasphere$linkis$rpc$BaseRPCSender$$getRPC(BaseRPCSender.scala:54)
at com.webank.wedatasphere.linkis.rpc.BaseRPCSender.send(BaseRPCSender.scala:105)
at com.webank.wedatasphere.linkis.engineconn.callback.service.AbstractEngineConnStartUpCallback.callback(EngineConnCallback.scala:39)
at com.webank.wedatasphere.linkis.engineconn.callback.hook.CallbackEngineConnHook.afterEngineServerStartFailed(CallbackEngineConnHook.scala:63)
at com.webank.wedatasphere.linkis.engineconn.launch.EngineConnServer$$anonfun$main$15.apply(EngineConnServer.scala:64)
at com.webank.wedatasphere.linkis.engineconn.launch.EngineConnServer$$anonfun$main$15.apply(EngineConnServer.scala:64)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at com.webank.wedatasphere.linkis.engineconn.launch.EngineConnServer$.main(EngineConnServer.scala:64)
at com.webank.wedatasphere.linkis.engineconn.launch.EngineConnServer.main(EngineConnServer.scala)
Solution: The conf in the /opt/kepler/work/engine/hadoop/workDir/9c28976e-63ba-4d9d-b85e-b37d84144596 directory is empty. lib and conf are detected by the system (linkis/lib/linkis-engineconn-plugins/python) when the microservice starts, and the python engine material package zip changes, and are automatically uploaded to the engine/engineConnPublickDir/ directory. The temporary solution to the problem is to copy the lib and conf content under linkis/lib/linkis-engineconn-plugins/python to the corresponding directory of engine/engineConnPublicDir/ (that is, the external link referenced in workDir/9c28976e-63ba-4d9d-b85e-b37d84144596 Under contents. The official solution needs to solve the problem that the change of the material package cannot be successfully uploaded to engineConnPublicDir.
Q24: After installing Exchangis0.5.0, click on the dss menu to enter a new page and prompt "Sorry, Page Not Found". F12 view has 404 exception
Error message: F12 view vue.runtime.esm.js:6785 GET http://10.0.xx.xx:29008/udes/auth?redirect=http%3A%2F%2F10.0.xx.xx%3A29008&dssurl= http%3A%2F%2F10.0.xx.xx%3A8088&cookies=bdp-user-ticket-id%3DM7UZXQP9Ld1xeftV5DUGYeHdOc9oAFgW2HLiVea4FcQ%3D%3B%20workspaceId%3D225 404 (Not Found)
Q25: There is an infinite loop in configuring atlas in HIVE, resulting in stack overflow
You need to add all the content jar packages and subdirectories under ${ATLAS_HOME}/atlas/hook/hive/ to the lib directory of hive engine, otherwise AtlasPluginClassLoader cannot find the correct implementation class and finds the one under hive-bridge-shim class, resulting in an infinite loop However, the current execution method of Linkis (1.0.2) does not support subdirectories under lib, and the code needs to be modified. Refer to: https://github.com/apache/linkis/pull/1058
Q26: Linkis1.0.X compiles based on spark3 hadoop3 hive3 or hdp3.1.4, please refer to:
https://github.com/lordk911/Linkis/commits/master After compiling, please recompile DSS according to the compiled package, keep the same version of scala, and use the family bucket for web modules
Q27 Linkis cannot get user name when executing jdbc task
2021-10-31 05:16:54.016 ERROR Task is Failed,errorMsg: NullPointerException: jdbc.username cannot be null. Source code: com.webank.wedatasphere.linkis.manager.engineplugin.jdbc.executer.JDBCEngineConnExecutor Received val properties = engineExecutorContext.getProperties.asInstanceOf[util.Map[String, String]] No jdbc.username parameter
Solution 1: Documentation: Temporary fixes for JDBC issues.note Link: http://note.youdao.com/noteshare?id=08163f429dd2e226a13877eba8bad1e3&sub=4ADEE86F433B4A59BBB20621A1C4B2AE Solution 2: Compare and modify this file https://github.com/apache/linkis/blob/319213793881b0329022cf4137ee8d4c502395c7/linkis-engineconn-plugins/engineconn-plugins/jdbc/src/main/scala/com/webank/wedatasphere/linkis/manager/engineplugin/jdbc/ executor/JDBCEngineConnExecutor.scala
Q28: After changing the hive version in the configuration before installation, the configuration of the management console still shows the version as 2.3.3

Solution 1: It is determined that there is a bug in the install.sh script, please change the hive-1.2.1 here to hive-2.3.3 and reinstall it. Solution 2: If you don’t want to reinstall, you need to change all the values of hive-2.3.3 in the label_value in the linkis_cg_manager_label table to the desired hive version Note: You are welcome to submit a PR to the github Linkis project to fix this problem, and then let us know, we will review and merge it into the code as soon as possible (currently unfixed, Deadline November 30, 2021)
Q29: When linkis-cli submits a task, it prompts GROUP BY clause; sql_mode=only_full_group_by error
_8_codeExec_8 com.webank.wedatasphere.linkis.orchestrator.ecm.exception.ECMPluginErrorException: errCode: 12003 ,desc: uathadoop01:9101_8 Failed to async get EngineNode MySQLSyntaxErrorException: Expression #6 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'dss_linkis.si.name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by ,ip: uathadoop01 ,port: 9104 ,serviceKind: linkis-cg-entrance
Reason: This error occurs in mysql version 5.7 and above. Problem: Because the configuration strictly implements the "SQL92 standard", the solution: enter the /etc/mysql directory to modify the my.cnf file and add code under [mysqld]: sql_mode = STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
Q30: An error is reported when the flink engine starts and the TokenCache is found
ERROR [main] com.webank.wedatasphere.linkis.engineconn.computation.executor.hook.ComputationEngineConnHook 57 error - EngineConnSever start failed! now exit. java.lang.NoClassDefFoundError: org/apache/hadoop/mapreduce/security/TokenCache Reason: The jar package hadoop-mapreduce-client-core.jar is missing under flink-enginecon lib, just copy a copy from hadoop lib.
Q31: When starting the flink engine/spark engine, the engine-entrance reports an error org.json4s.JsonAST$JNothing$ cannot be cast to org.json4s.JsonAST$JString
The reason is that linkis-manager reports an error in the yarn queue to obtain an exception Solution: Modify the linkis_cg_rm_external_resource_provider table and modify the yarn queue information corresponding to config
Q32: ClassNotFoundException is reported when the function script is executed

Reason: linkis creates a function by adding the path of the function to the classPath, and then executing create temporary function. . . Statement, when submitting tasks to the yarn cluster in this way, the jar package of the function will not be uploaded to hdfs, resulting in class loading failure!
Solution: Modify the method of generating function statements, or use HiveAddJarsEngineHook to solve it. Here, modify the constructCode method of JarUdfEngineHook. After packaging replace all
override protected def constructCode(udfInfo: UDFInfo): String = {
"%sql\n" + "add jar " + udfInfo.getPath + "\n%sql\n" + udfInfo.getRegisterFormat
}
Q33: Failed to start bean 'webServerStartStop when Linkis executes Spark task in CDH environment
Detailed log:
Caused by: java.lang.IllegalStateException
at org.eclipse.jetty.servlet.ServletHolder.setClassFrom(ServletHolder.java:300) ~[jetty-servlet-9.4.48.v20220622.jar:9.4.48.v20220622]
at org.eclipse.jetty.servlet.ServletHolder.doStart(ServletHolder.java:347) ~[jetty-servlet-9.4.48.v20220622.jar:9.4.48.v20220622]
at org.eclipse.jetty.util.component.AbstractLifeCycle.start(AbstractLifeCycle.java:73) ~[jetty-util-9.4.48.v20220622.jar:9.4.48.v20220622]
at org.eclipse.jetty.servlet.ServletHandler.lambda$initialize$0(ServletHandler.java:749) ~[jetty-servlet-9.4.48.v20220622.jar:9.4.48.v20220622]
at java.util.stream.SortedOps$SizedRefSortingSink.end(SortedOps.java:357) ~[?:1.8.0_292]
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:483) ~[?:1.8.0_292]
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:472) ~[?:1.8.0_292]
at java.util.stream.StreamSpliterators$WrappingSpliterator.forEachRemaining(StreamSpliterators.java:313) ~[?:1.8.0_292]
at java.util.stream.Streams$ConcatSpliterator.forEachRemaining(Streams.java:743) ~[?:1.8.0_292]
at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:647) ~[?:1.8.0_292]
at org.eclipse.jetty.servlet.ServletHandler.initialize(ServletHandler.java:774) ~[jetty-servlet-9.4.48.v20220622.jar:9.4.48.v20220622]
at org.springframework.boot.web.embedded.jetty.JettyEmbeddedWebAppContext$JettyEmbeddedServletHandler.deferredInitialize(JettyEmbeddedWebAppContext.java:46) ~[spring-boot-2.3.12.RELEASE.jar:2.3.12.RELEASE]
at
Reason: This is due to the conflict between the classPath and Linkis that CDH-Spark depends on at the bottom. Solution: On the machine where linkis is deployed, you can check the classPath in spark-env.sh, comment it out, and run it again. For details, please refer to 3282
Q34: An error is reported when running the flink task: Failed to create engineConnPlugin: com.webank.wedatasphere.linkis.engineplugin.hive.HiveEngineConnPluginjava.lang.ClassNotFoundException: com.webank.wedatasphere.linkis.engineplugin.hive.HiveEngineConnPlugin

Reason: The configuration file in the conf in the flink engine directory is empty, and the default configuration is read (by default, the hived engine configuration is read), delete the conf about flink in the configuration table and restart ecp