CS Search 架构
CSSearch架构
总体架构
如下图所示:
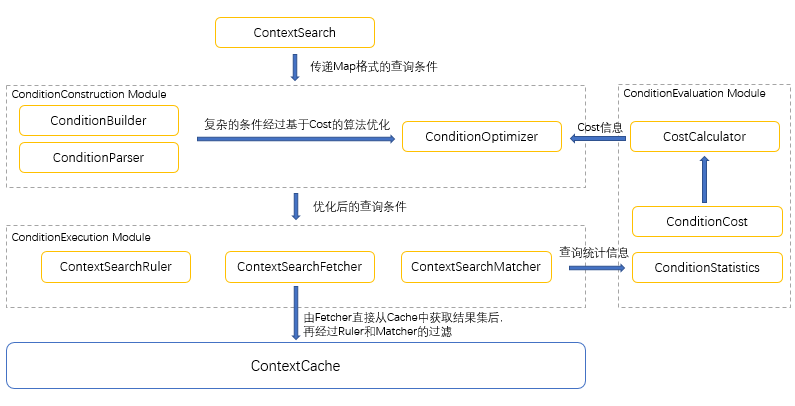
ContextSearch:查询入口,接受Map形式定义的查询条件,根据条件返回相应的结果。
构建模块:每个条件类型对应一个Parser,负责将Map形式的条件转换成Condition对象,具体通过调用ConditionBuilder的逻辑实现。具有复杂逻辑关系的Condition会通过ConditionOptimizer进行基于代价的算法优化查询方案。
执行模块:从Cache中,筛选出与条件匹配的结果。根据查询目标的不同,分为Ruler、Fetcher和Match而三种执行模式,具体逻辑在后文描述。
评估模块:负责条件执行代价的计算和历史执行状况的统计。
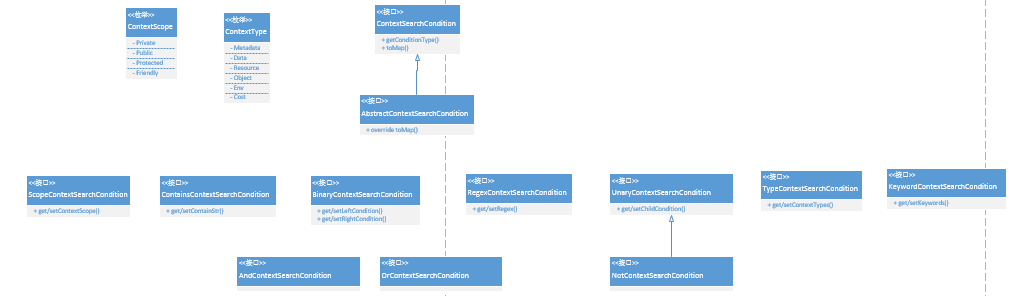
查询条件定义(ContextSearchCondition)
一个查询条件,规定了该如何从一个ContextKeyValue集合中,筛选出符合条件的那一部分。查询条件可以通过逻辑运算构成更加复杂的查询条件。
支持ContextType、ContextScope、KeyWord的匹配
分别对应一个Condition类型
在Cache中,这些都应该有相应的索引
支持对key的contains/regex匹配模式
ContainsContextSearchCondition:包含某个字符串
RegexContextSearchCondition:匹配某个正则表达式
支持or、and和not的逻辑运算
- 一元运算UnaryContextSearchCondition:
支持单个参数的逻辑运算,比如NotContextSearchCondition
- 二元运算BinaryContextSearchCondition:
支持两个参数的逻辑运算,分别定义为LeftCondition和RightCondition,比如OrContextSearchCondition和AndContextSearchCondition
每个逻辑运算均对应一个上述子类的实现类
该部分的UML类图如下:
查询条件的构建
支持通过ContextSearchConditionBuilder构建:构建时,如果同时声明多项ContextType、ContextScope、KeyWord、contains/regex的匹配,自动以And逻辑运算连接
支持Condition之间进行逻辑运算,返回新的Condition:And,Or和Not(考虑condition1.or(condition2)的形式,要求Condition顶层接口定义逻辑运算方法)
支持通过每个底层实现类对应的ContextSearchParser从Map构建
查询条件的执行
查询条件的三种作用方式:
Ruler:从一个Array中筛选出符合条件的ContextKeyValue子Array
Matcher:判断单个ContextKeyValue是否符合条件
Fetcher:从ContextCache里筛选出符合条件的ContextKeyValue的Array
每个底层的Condition都有对应的Execution,负责维护相应的Ruler、Matcher、Fetcher。
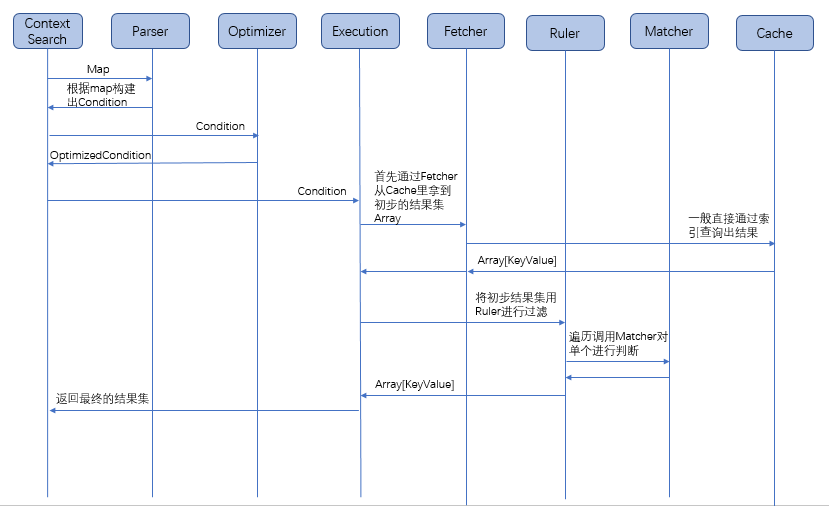
查询入口ContextSearch
提供search接口,接收Map作为参数,从Cache中筛选出对应的数据。
通过Parser,将Map形式的条件转换为Condition对象
通过Optimizer,获取代价信息,并根据代价信息确定查询的先后顺序
通过对应的Execution,执行相应的Ruler/Fetcher/Matcher逻辑后,得到搜索结果
查询优化
OptimizedContextSearchCondition维护条件的Cost和Statistics信息:
Cost信息:由CostCalculator负责判断某个Condition是否能够计算出Cost,如果可以计算,则返回对应的Cost对象
Statistics信息:开始/结束/执行时间、输入行数、输出行数
实现一个CostContextSearchOptimizer,其optimize方法以Condition的代价为依据,对Condition进行调优,转换为一个OptimizedContextSearchCondition对象。具体逻辑描述如下:
- 将一个复杂的Condition,根据逻辑运算的组合,拆解成一个树形结构,每个叶子节点均为一个最基本的简单Condition;每个非叶子节点均为一个逻辑运算。
如下图所示的树A,就是一个由ABCDE这五个简单条件,通过各种逻辑运算组合成的一个复杂条件。
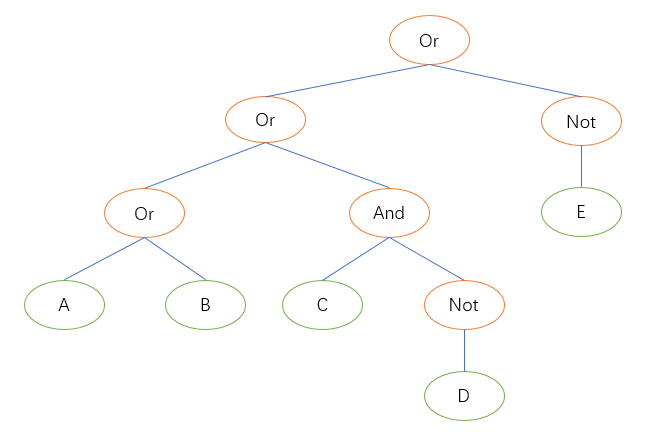
- 这些Condition的执行,事实上就是深度优先、从左到右遍历这个树。而且根据逻辑运算的交换规律,Condition树中一个节点的子节点的左右顺序可以互换,因此可以穷举出所有可能的执行顺序下的所有可能的树。
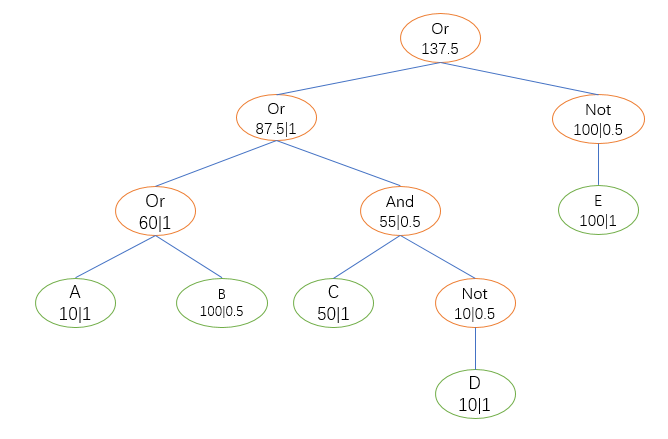
如下图所示的树B,就是上述树A的另一个可能的顺序,与树A的执行结果完全一致,只是各部分的执行顺序有所调整。
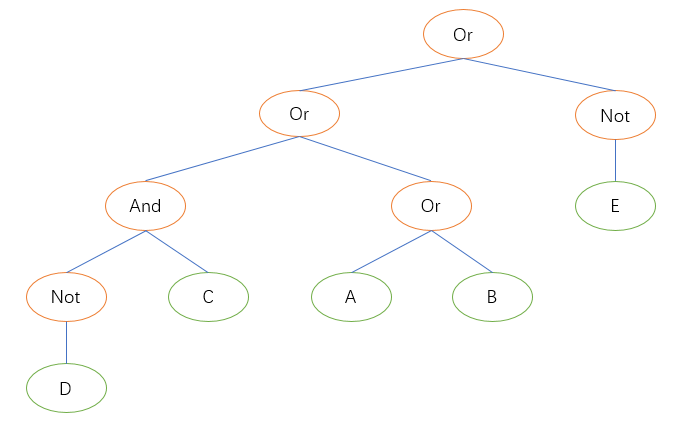
- 针对每一个树,从叶子节点开始计算代价,归集到根节点,即为该树的最终代价,最终得出代价最小的那个树,作为最优执行顺序。
计算节点代价的规则如下:
针对叶子节点,每个节点有两个属性:代价(Cost)和权重(Weight)。Cost即为CostCalculator计算出的代价,Weight是根据节点执行先后顺序的不同赋予的,当前默认左边为1,右边为0.5,后续看如何调整(赋予权重的原因是,左边的条件在一些情况下已经可以直接决定整个组合逻辑的匹配与否,所以右边的条件并非所有情况下都要执行,实际开销就需要减少一定的比例)
针对非叶子节点,Cost=所有子节点的Cost×Weight的总和;Weight的赋予逻辑与叶子节点一致。
以树A和树B为例子,分别计算出这两个树的代价,如下图所示,节点中的数字为Cost|Weight,假设ABCDE这5个简单条件的Cost为10、100、50、10和100。由此可以得出,树B的代价小于树A,为更优方案。

用CostCalculator衡量简单条件的Cost的思路:
作用在索引上的条件:根据索引值的分布来确定代价。比如当条件A从Cache中get出来的Array长度是100,条件B为200,那么条件A的代价小于B。
需要遍历的条件:
根据条件本身匹配模式给出一个初始Cost:如Regex为100,Contains为10等(具体数值等实现时根据情况调整)
根据历史查询的效率,在初始Cost的基础上进行不断调整后,得到实时的Cost。单位时间吞吐量