Linkis任务执行流程
计算任务(Job)的提交执行是Linkis提供的核心能力,它几乎串通了Linkis计算治理架构中的所有模块,在Linkis之中占据核心地位。
我们将用户的计算任务从客户端提交开始,到最后的返回结果为止,整个流程分为三个阶段:提交 -> 准备 -> 执行,如下图所示:
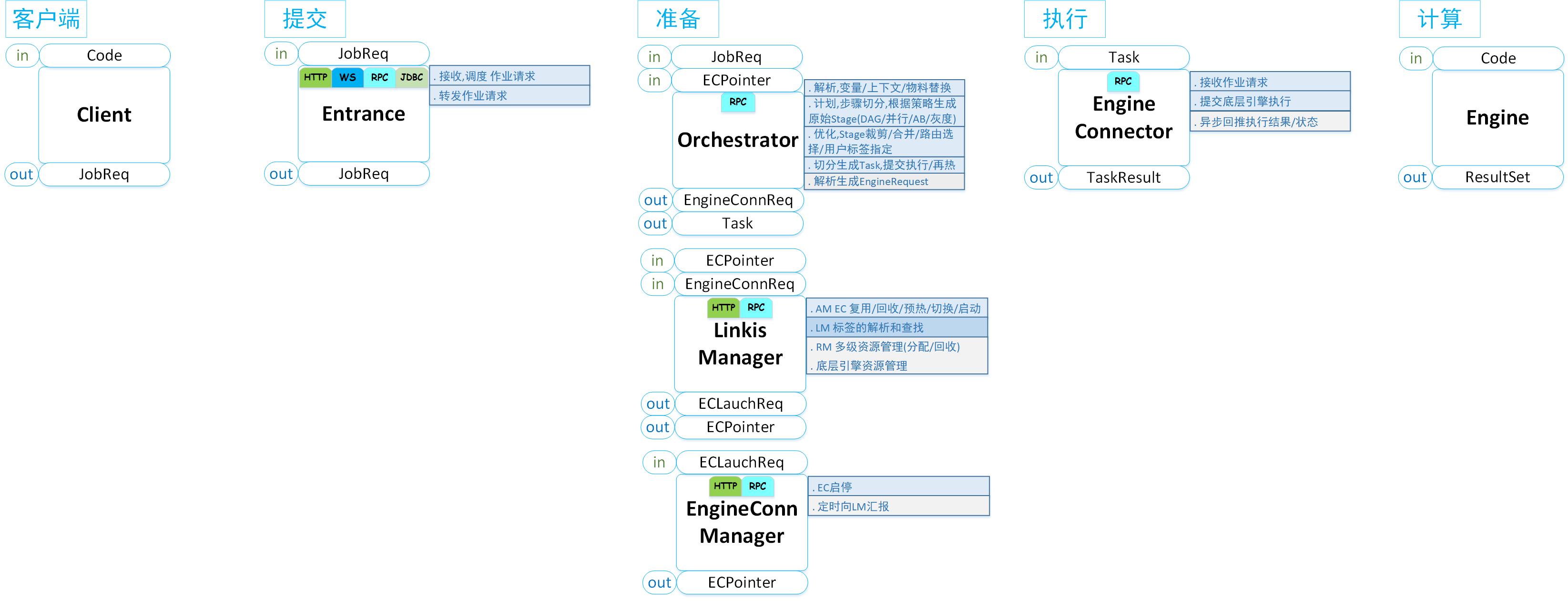
其中:
Entrance作为提交阶段的入口,提供任务的接收、调度和Job信息的转发能力,是所有计算型任务的统一入口,它将把计算任务转发给Orchestrator进行编排和执行;
Orchestrator作为准备阶段的入口,主要提供了Job的解析、编排和执行能力。。
Linkis Manager:是计算治理能力的管理中枢,主要的职责为:
ResourceManager:不仅具备对Yarn和Linkis EngineConnManager的资源管理能力,还将提供基于标签的多级资源分配和回收能力,让ResourceManager具备跨集群、跨计算资源类型的全资源管理能力;
AppManager:统筹管理所有的EngineConnManager和EngineConn,包括EngineConn的申请、复用、创建、切换、销毁等生命周期全交予AppManager进行管理;
LabelManager:将基于多级组合标签,为跨IDC、跨集群的EngineConn和EngineConnManager路由和管控能力提供标签支持;
EngineConnPluginServer:对外提供启动一个EngineConn的所需资源生成能力和EngineConn的启动命令生成能力。
EngineConnManager:是EngineConn的管理器,提供引擎的生命周期管理,同时向RM汇报负载信息和自身的健康状况。
EngineConn:是Linkis与底层计算存储引擎的实际连接器,用户所有的计算存储任务最终都会交由EngineConn提交给底层计算存储引擎。根据用户的不同使用场景,EngineConn提供了交互式计算、流式计算、离线计算、数据存储任务的全栈计算能力框架支持。
接下来,我们将详细介绍计算任务从 提交 -> 准备 -> 执行 的三个阶段。
一、提交阶段
提交阶段主要是Client端 -> Linkis Gateway -> Entrance的交互,其流程如下:

- 首先,Client(如前端或客户端)发起Job请求,Job请求信息精简如下 (关于Linkis的具体使用方式,请参考 如何使用Linkis):
POST /api/rest_j/v1/entrance/submit
{
"executionContent": {"code": "show tables", "runType": "sql"},
"params": {"variable": {}, "configuration": {}}, //非必须
"source": {"scriptPath": "file:///1.hql"}, //非必须,仅用于记录代码来源
"labels": {
"engineType": "spark-2.4.3", //指定引擎
"userCreator": "johnnwnag-IDE" // 指定提交用户和提交系统
}
}
Linkis-Gateway接收到请求后,根据URI
/api/rest_j/v1/${serviceName}/.+中的serviceName,确认路由转发的微服务名,这里Linkis-Gateway会解析出微服务名为entrance,将Job请求转发给Entrance微服务。需要说明的是:如果用户指定了路由标签,则在转发时,会根据路由标签选择打了相应标签的Entrance微服务实例进行转发,而不是随机转发。Entrance接收到Job请求后,会先简单校验请求的合法性,然后通过RPC调用JobHistory对Job的信息进行持久化,然后将Job请求封装为一个计算任务,放入到调度队列之中,等待被消费线程消费。
调度队列会为每个组开辟一个消费队列 和 一个消费线程,消费队列用于存放已经初步封装的用户计算任务,消费线程则按照FIFO的方式,不断从消费队列中取出计算任务进行消费。目前默认的分组方式为 Creator + User(即提交系统 + 用户),因此,即便是同一个用户,只要是不同的系统提交的计算任务,其实际的消费队列和消费线程都完全不同,完全隔离互不影响。(温馨提示:用户可以按需修改分组算法)
消费线程取出计算任务后,会将计算任务提交给Orchestrator,由此正式进入准备阶段。
二、 准备阶段
准备阶段主要有两个流程,一是向LinkisManager申请一个可用的EngineConn,用于接下来的计算任务提交执行,二是Orchestrator对Entrance提交过来的计算任务进行编排,将一个用户计算请求,通过编排转换成一个物理执行树,然后交给第三阶段的执行阶段去真正提交执行。
2.1 向LinkisManager申请可用EngineConn
如果在LinkisManager中,该用户存在可复用的EngineConn,则直接锁定该EngineConn,并返回给Orchestrator,整个申请流程结束。
如何定义可复用EngineConn?指能匹配计算任务的所有标签要求的,且EngineConn本身健康状态为Healthy(负载低且实际EngineConn状态为Idle)的,然后再按规则对所有满足条件的EngineConn进行排序选择,最终锁定一个最佳的EngineConn。
如果该用户不存在可复用的EngineConn,则此时会触发EngineConn新增流程,关于EngineConn新增流程,请参阅:EngineConn新增流程 。
2.2 计算任务编排
Orchestrator主要负责将一个计算任务(JobReq),编排成一棵可以真正执行的物理执行树(PhysicalTree),并提供Physical树的执行能力。
这里先重点介绍Orchestrator的计算任务编排能力,如下图:
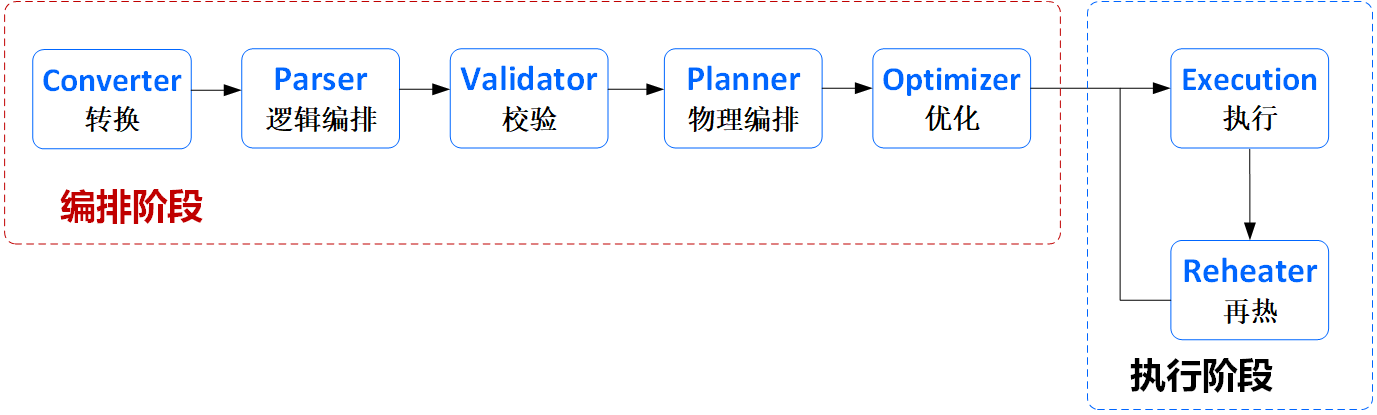
其主要流程如下:
Converter(转换):完成对用户提交的JobReq(任务请求)转换为Orchestrator的ASTJob,该步骤会对用户提交的计算任务进行参数检查和信息补充,如变量替换等;
Parser(解析):完成对ASTJob的解析,将ASTJob拆成由ASTJob和ASTStage组成的一棵AST树。
Validator(校验): 完成对ASTJob和ASTStage的检验和信息补充,如代码检查、必须的Label信息补充等。
Planner(计划):将一棵AST树转换为一棵Logical树。此时的Logical树已经由LogicalTask组成,包含了整个计算任务的所有执行逻辑。
Optimizer(优化阶段):将一棵Logical树转换为Physica树,并对Physical树进行优化。
一棵Physical树,其中的很多节点都是计算策略逻辑,只有中间的ExecTask,才真正封装了将用户计算任务提交给EngineConn进行提交执行的执行逻辑。如下图所示:
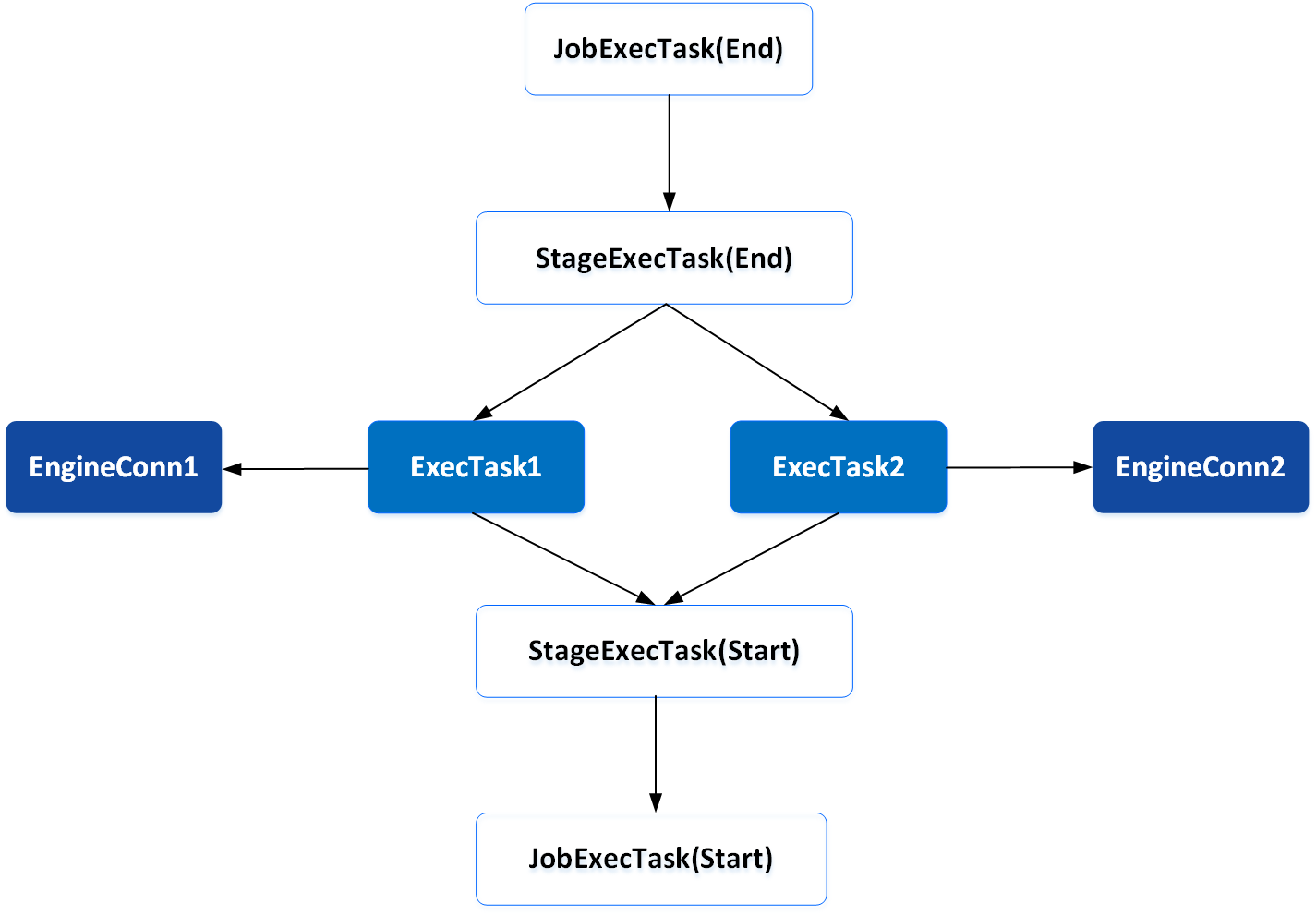
不同的计算策略,其Physical树中的JobExecTask 和 StageExecTask所封装的执行逻辑各不相同。
如多活计算策略下,用户提交的一个计算任务,其提交给不同集群的EngineConn进行执行的执行逻辑封装在了两个ExecTask中,而相关的多活策略逻辑则体现在了两个ExecTask的父节点StageExecTask(End)之中。
这里举多活计算策略下的多读场景。
多读时,实际只要求一个ExecTask返回结果,该Physical树就可以标记为执行成功并返回结果了,但Physical树只具备按依赖关系进行依次执行的能力,无法终止某个节点的执行,且一旦某个节点被取消执行或执行失败,则整个Physical树其实会被标记为执行失败,这时就需要StageExecTask(End)来做一些特殊的处理,来保证既可以取消另一个ExecTask,又能把执行成功的ExecTask所产生的结果集继续往上传,让Physical树继续往上执行。这就是StageExecTask所代表的计算策略执行逻辑。
Linkis Orchestrator的编排流程与很多SQL解析引擎(如Spark、Hive的SQL解析器)存在相似的地方,但实际上,Linkis Orchestrator是面向计算治理领域针对用户不同的计算治理需求,而实现的解析编排能力,而SQL解析引擎是面向SQL语言的解析编排。这里做一下简单区分:
Linkis Orchestrator主要想解决的,是不同计算任务对计算策略所引发出的编排需求。如:用户想具备多活的能力,则Orchestrator会为用户提交的一个计算任务,基于“多活”的计算策略需求,编排出一棵Physical树,从而做到往多个集群去提交执行这个计算任务,并且在构建整个Physical树的过程中,已经充分考虑了各种可能存在的异常场景,并都已经体现在了Physical树中。
Linkis Orchestrator的编排能力与编程语言无关,理论上只要是Linkis已经对接的引擎,其支持的所有编程语言都支持编排;而SQL解析引擎只关心SQL的解析和执行,只负责将一条SQL解析成一颗可执行的Physical树,最终计算出结果。
Linkis Orchestrator也具备对SQL的解析能力,但SQL解析只是Orchestrator Parser针对SQL这种编程语言的其中一种解析实现。Linkis Orchestrator的Parser也考虑引入Apache Calcite对SQL进行解析,支持将一条跨多个计算引擎(必须是Linkis已经对接的计算引擎)的用户SQL,拆分成多条子SQL,在执行阶段时分别提交给对应的计算引擎进行执行,最后选择一个合适的计算引擎进行汇总计算。
经过了Linkis Orchestrator的解析编排后,用户的计算任务已经转换成了一颗可被执行的Physical树。Orchestrator会将该Physical树提交给Orchestrator的Execution模块,进入最后的执行阶段。
三、执行阶段
执行阶段主要分为如下两步,这两步是Linkis Orchestrator提供的最后两阶段的能力:
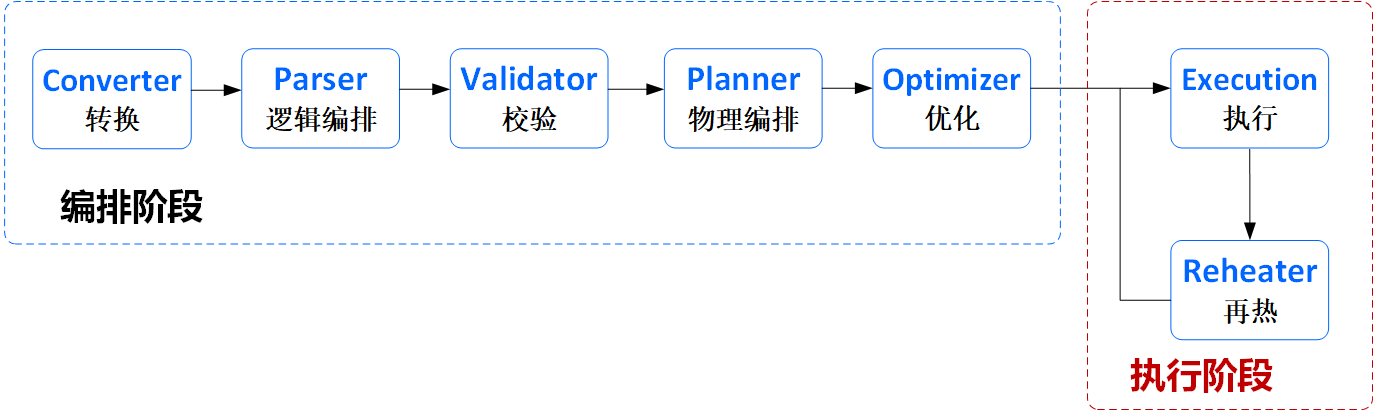
其主要流程如下:
Execution(执行):解析Physical树的依赖关系,按照依赖从叶子节点开始依次执行。
Reheater(再热):一旦Physical树有节点执行完成,都会触发一次再热。再热允许依照Physical树的实时执行情况,动态调整Physical树,继续进行执行。如:检测到某个叶子节点执行失败,且该叶子节点支持重试(如失败原因是抛出了ReTryExecption),则自动调整Physical树,在该叶子节点上面添加一个内容完全相同的重试父节点。
我们回到Execution阶段,这里重点介绍封装了将用户计算任务提交给EngineConn的ExecTask节点的执行逻辑。
前面有提到,准备阶段的第一步,就是向LinkisManager获取一个可用的EngineConn,ExecTask拿到这个EngineConn后,会通过RPC请求,将用户的计算任务提交给EngineConn。
EngineConn接收到计算任务之后,会通过线程池异步提交给底层的计算存储引擎,然后马上返回一个执行ID。
ExecTask拿到这个执行ID后,后续可以通过该执行ID异步去拉取计算任务的执行情况(如:状态、进度、日志、结果集等)。
同时,EngineConn会通过注册的多个Listener,实时监听底层计算存储引擎的执行情况。如果该计算存储引擎不支持注册Listener,则EngineConn会为计算任务启动守护线程,定时向计算存储引擎拉取执行情况。
EngineConn将拉取到的执行情况,通过RCP请求,实时传回Orchestrator所在的微服务。
该微服务的Receiver接收到执行情况后,会通过ListenerBus进行广播,Orchestrator的Execution消费该事件并动态更新Physical树的执行情况。
计算任务所产生的结果集,会在EngineConn端就写入到HDFS等存储介质之中。EngineConn通过RPC传回的只是结果集路径,Execution消费事件,并将获取到的结果集路径通过ListenerBus进行广播,使Entrance向Orchestrator注册的Listener能消费到该结果集路径,并将结果集路径写入持久化到JobHistory之中。
EngineConn端的计算任务执行完成后,通过同样的逻辑,会触发Execution更新Physical树该ExecTask节点的状态,使得Physical树继续往上执行,直到整棵树全部执行完成。这时Execution会通过ListenerBus广播计算任务执行完成的状态。
Entrance向Orchestrator注册的Listener消费到该状态事件后,向JobHistory更新Job的状态,整个任务执行完成。
最后,我们再来看下Client端是如何得知计算任务状态变化,并及时获取到计算结果的,具体如下图所示:
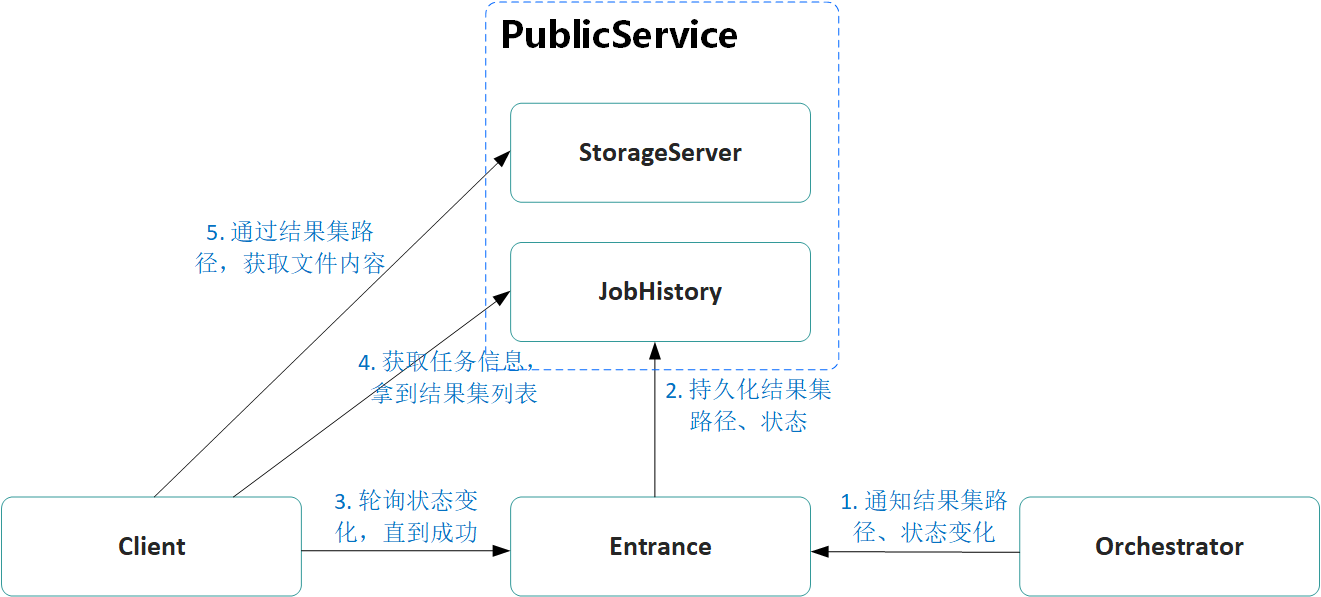
具体流程如下:
Client端定时轮询请求Entrance,获取计算任务的状态。
一旦发现状态翻转为成功,则向JobHistory发送获取Job信息的请求,拿到所有的结果集路径
通过结果集路径向PublicService发起查询文件内容的请求,获取到结果集的内容。
自此,整个Job的提交 -> 准备 -> 执行 三个阶段全部完成。