总览
1 Linkis的设计初衷
大数据开源生态圈几乎每个组件都有自己的一套用户权限管理、资源管理、元数据管理、独立的API接入方式和使用方式。
而且各种新的组件还在不断出现。
但是,用户的业务需求通常需要多个开源组件协同处理才能实现。
为了一个业务需求,用户需要学习多个产品的使用手册,需要在多个产品上做重复的定制化开发,才能真正将开源组件引入到实际的生产环境中。
这给用户带来了极其高昂的学习成本和额外工作量,运维方面也需要大量重复的维护管理工作。
同时,上层的功能工具产品和底层的计算存储系统耦合度过高,层次结构、调用关系不够清晰和解耦,导致底层环境一旦发生任何改变,都会直接影响业务产品的正常使用。
如何提供一套统一的数据中间件,对接上层应用工具,屏蔽掉底层的各种调用和使用细节,真正做到让业务用户只需关注业务实现细节,就算底层大数据平台机房扩建、整体搬迁都不受影响,是Linkis的设计初衷!
2 Linkis的技术架构
如上图所示,我们基于目前流行的SpringCloud微服务技术,新建了多个微服务集群,来提供高可用能力。
每个微服务集群各自承担系统的一部分功能职责,我们对其进行了如下明确的划分。如:
统一作业执行服务:一个分布式的REST/WebSocket服务,用于接收用户提交的各种脚本请求。
目前支持的计算引擎有:Spark、Python、TiSpark、Hive和Shell等。
支持的脚本语言有:SparkSQL、Spark Scala、Pyspark、R、Python、HQL和Shell等;
更多关于统一作业执行服务的信息,请查看UJES架构设计文档
资源管理服务: 支持实时管控每个系统和用户的资源使用情况,限制系统和用户的资源使用量和并发数,并提供实时的资源动态图表,方便查看和管理系统和用户的资源;
目前已支持的资源类型:Yarn队列资源、服务器(CPU和内存)、用户并发个数等。
更多关于资源管理服务的信息,请查看RM架构设计文档
应用管理服务(开源版本暂无):管理所有系统的所有用户应用,包括离线批量应用、交互式查询应用和实时流式应用,为离线和交互式应用提供强大的复用能力,并提供应用全生命周期管理,自动释放用户多余的空闲应用;统一存储服务:通用的IO架构,能快速对接各种存储系统,提供统一调用入口,支持所有常用格式数据,集成度高,简单易用;
更多统一存储服务的信息,请查看[Storage架构设计文档]
统一上下文服务:统一用户和系统资源文件(JAR、ZIP、Properties等),用户、系统、计算引擎的参数和变量统一管理,一处设置,处处自动引用;
物料库:系统和用户级物料管理,可分享和流转,支持全生命周期自动管理;
元数据服务:实时的库表结构和分区情况展示。
依赖于这些微服务的相互协作,对外构建一个集中的、统一的大数据平台服务。
通过这些服务的构建,我们改善了整个大数据平台对外服务的方式和流程。
3 Linkis业务架构
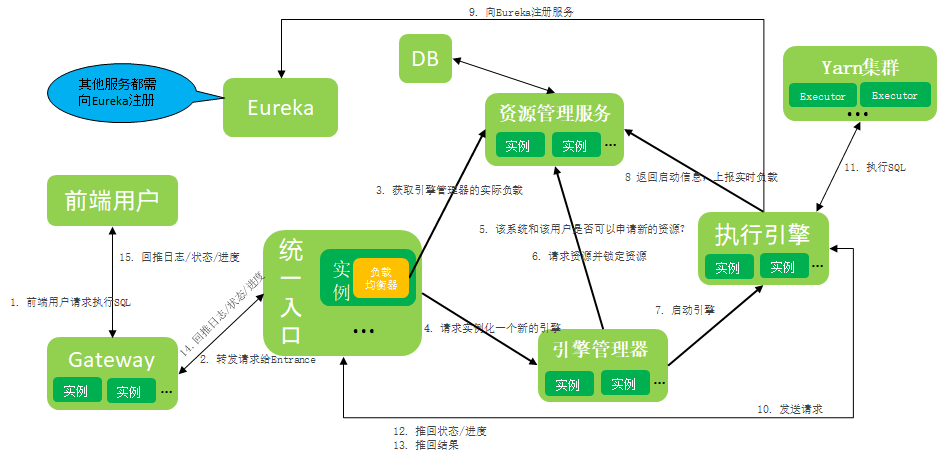
名词解释:
1) Gateway网关:
基于Spring Cloud Gateway进行了插件化功能增强,新增了WebSocket一对多能力的网关服务,主要用于解析和路由转发用户的请求到指定微服务。
2) 统一入口:
统一入口是用户某一类引擎作业的Job生命周期管理者。
从作业生成到提交到执行引擎,再到作业信息反馈给用户和作业关闭,Entrance管理了一个作业的全生命周期。
3) 引擎管理器:
引擎管理器负责管理引擎的全生命周期。
负责向资源管理服务申请和锁定资源,并实例化新的引擎,也负责监控引擎的生命状态。
4) 执行引擎:
执行引擎是真正执行用户作业的微服务,它由引擎管理器启动。
为了提升交互性能,引擎服务是直接跟提交给它作业的统一入口进行交互,将作业正确执行,并反馈用户需要的各种信息,如日志、进度、状态和结果集等。
5) 资源管理服务
实时管控每个系统和每个用户的资源使用情况,管理微服务集群的资源使用和实际负载,限制系统和用户的资源使用量和并发数。
6) Eureka
Eureka是Netflix开发的服务发现框架,SpringCloud将它集成在其子项目spring-cloud-netflix中,以实现SpringCloud的服务发现功能。
每个微服务都内置了Eureka Client,可以访问Eureka Server,实时获得服务发现的能力。
4 Linkis处理流程
下面开始介绍用户在上层系统提交了一个SQL,Linkis是如何执行并返回结果的。
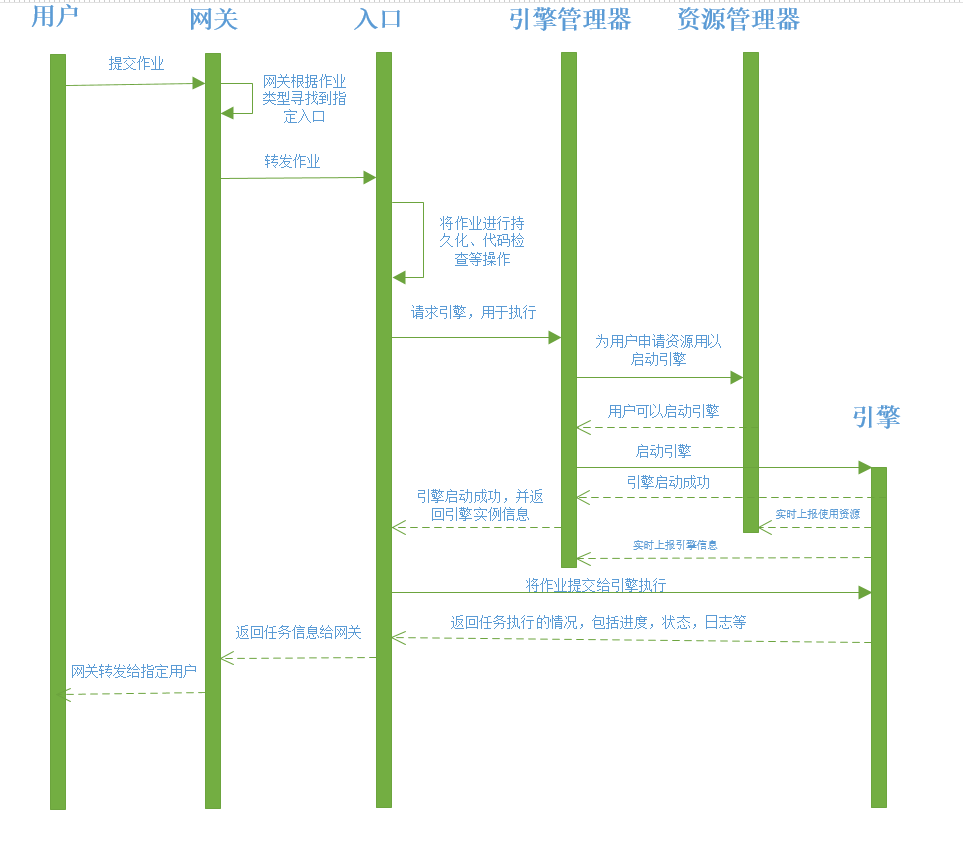
上层系统的用户提交一个SQL,先经过Gateway,Gateway负责解析用户请求,并路由转发给合适的统一入口Entrance
entrance会先寻找该系统的该用户是否存在可用的Spark引擎服务,如果存在,则直接将请求提交给Spark引擎服务
不存在可用Spark引擎服务,开始通过Eureka的服务注册发现功能,拿到所有的引擎管理器列表,通过请求RM实时获取引擎管理器的实际负载
Entrance拿到负载最低的引擎管理器,开始要求引擎管理器启动一个Spark引擎服务
引擎管理器接收到请求,开始询问RM该系统下的该用户,是否可以启动新引擎
如果可以启动,则开始请求资源并锁定;否则返回启动失败的异常给到Entrance
锁定资源成功,开始启动新的spark引擎服务;启动成功后,将新Spark新引擎返回给Entrance
Entrance拿到新引擎后,开始向新引擎请求执行SQL
Spark新引擎接收SQL请求,开始向Yarn提交执行SQL,并实时推送日志、进度和状态给Entrance
Entrance将获取的日志、进度和状态实时推送给Gateway
Gateway回推日志、进度和状态给前端
一旦SQL执行成功,Engine主动将结果集推给Entrance,Entrance通知前端拿取结果。
关于Entrance/EngineManager/Engine异常情况下的设计方案,请查看UJES架构设计文档