Overview
1 The original intention of Linkis
Almost every component of the big data open source ecosystem has its own set of user rights management, resource management, metadata management, independent API access and usage methods.
And various new components continue to appear.
However, the user's business needs usually require the collaborative processing of multiple open source components to achieve.
For a business requirement, users need to learn the manuals of multiple products, and need to do repeated customized development on multiple products, in order to truly introduce open source components into the actual production environment.
This has brought extremely high learning costs and extra workload to users, and a large amount of repeated maintenance and management work is also required for operation and maintenance.
At the same time, the coupling between the upper-level functional tool products and the underlying computing storage system is too high, and the hierarchical structure and calling relationship are not clear and decoupled. As a result, any changes in the underlying environment will directly affect the normal use of business products.
How to provide a set of unified data middleware, docking with upper-level application tools, shielding various calls and usage details at the bottom, and truly enabling business users to only pay attention to the details of business implementation, even if the underlying big data platform's computer room expansion and overall relocation are both Not affected, is the original intention of Linkis!
2 Linkis Technical Architecture
As shown in the figure above, we have built multiple microservice clusters based on the current popular SpringCloud microservice technology to provide high availability capabilities.
Each microservice cluster bears part of the system's functional responsibilities, and we have made the following clear divisions. like:
-Unified Job Execution Service: A distributed REST/WebSocket service for receiving various script requests submitted by users.
Currently supported computing engines are: Spark, Python, TiSpark, Hive, Shell, etc.
Supported scripting languages are: SparkSQL, Spark Scala, Pyspark, R, Python, HQL and Shell, etc.;
For more information about unified job execution services, please check UJES Architecture Design Document
-Resource Management Service: Support real-time management and control of the resource usage of each system and user, limit the resource usage and concurrency of the system and users, and provide real-time resource dynamic charts to facilitate viewing and managing the system and users resource;
Currently supported resource types: Yarn queue resources, servers (CPU and memory), number of concurrent users, etc.
For more information about resource management services, please check RM Architecture Design Document
-~~Application management service (not available in open source version): Manage all user applications of all systems, including offline batch applications, interactive query applications, and real-time streaming applications, providing powerful replication for offline and interactive applications It also provides application lifecycle management, and automatically releases users’ redundant idle applications; ~~
-Unified storage service: Universal IO architecture, which can quickly connect to various storage systems, provide a unified call entry, support all commonly used format data, high integration, and easy to use;
For more information on unified storage services, please check [Storage Architecture Design Document]
-Unified Context Service: Unified user and system resource files (JAR, ZIP, Properties, etc.), unified management of parameters and variables of users, systems, and calculation engines, one setting and automatic reference everywhere;
-Material Library: System and user-level material management, which can be shared and transferred, and supports automatic management of the entire life cycle;
-Metadata Service: Real-time display of database table structure and partition status.
Rely on the mutual cooperation of these microservices to build a centralized and unified big data platform service externally.
Through the construction of these services, we have improved the external service methods and processes of the entire big data platform.
3 Linkis Business Architecture
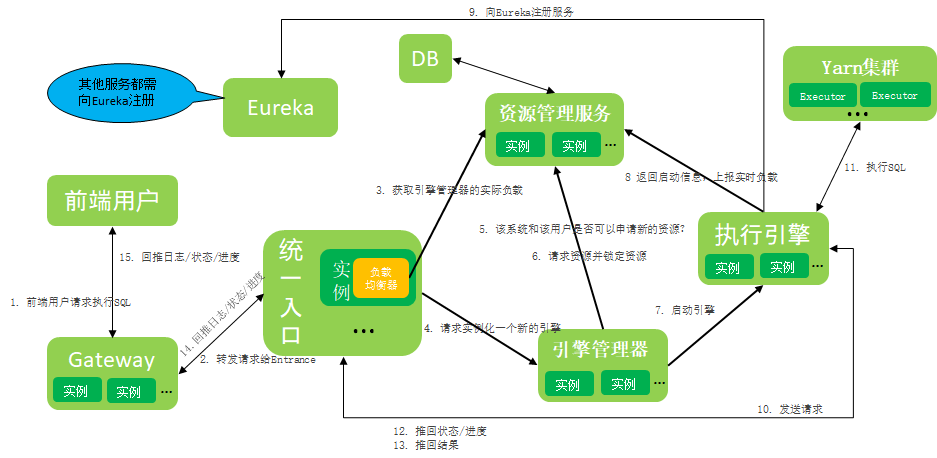
Glossary:
1) Gateway:
Based on Spring Cloud Gateway, the plug-in function is enhanced, and a gateway service with WebSocket one-to-many capability is added, which is mainly used to parse and route user requests to designated microservices.
2) Unified entrance:
The unified portal is the job lifecycle manager of a certain type of engine operation of the user.
From job generation to submission to the execution engine, to job information feedback to users and job closure, Entrance manages the entire life cycle of a job.
3) Engine Manager:
The engine manager is responsible for managing the entire life cycle of the engine.
Responsible for applying for and locking resources from the resource management service, instantiating a new engine, and monitoring the life state of the engine.
4) Execution engine:
The execution engine is a microservice that actually executes user jobs, and it is started by the engine manager.
In order to improve the interaction performance, the engine service directly interacts with the unified portal of the job submitted to it, executes the job correctly, and feeds back various information required by the user, such as log, progress, status, and result set.
5) Resource Management Service
Real-time control of the resource usage of each system and each user, manage the resource usage and actual load of the microservice cluster, and limit the resource usage and concurrency of the system and users.
6) Eureka
Eureka is a service discovery framework developed by Netflix. Spring Cloud integrates it into its sub-project spring-cloud-netflix to realize the service discovery function of Spring Cloud.
Each microservice has a built-in Eureka Client, which can access Eureka Server and obtain the ability of service discovery in real time.
4 Linkis processing flow
Now let's introduce how the user submits a SQL in the upper system, and how Linkis executes and returns the result.
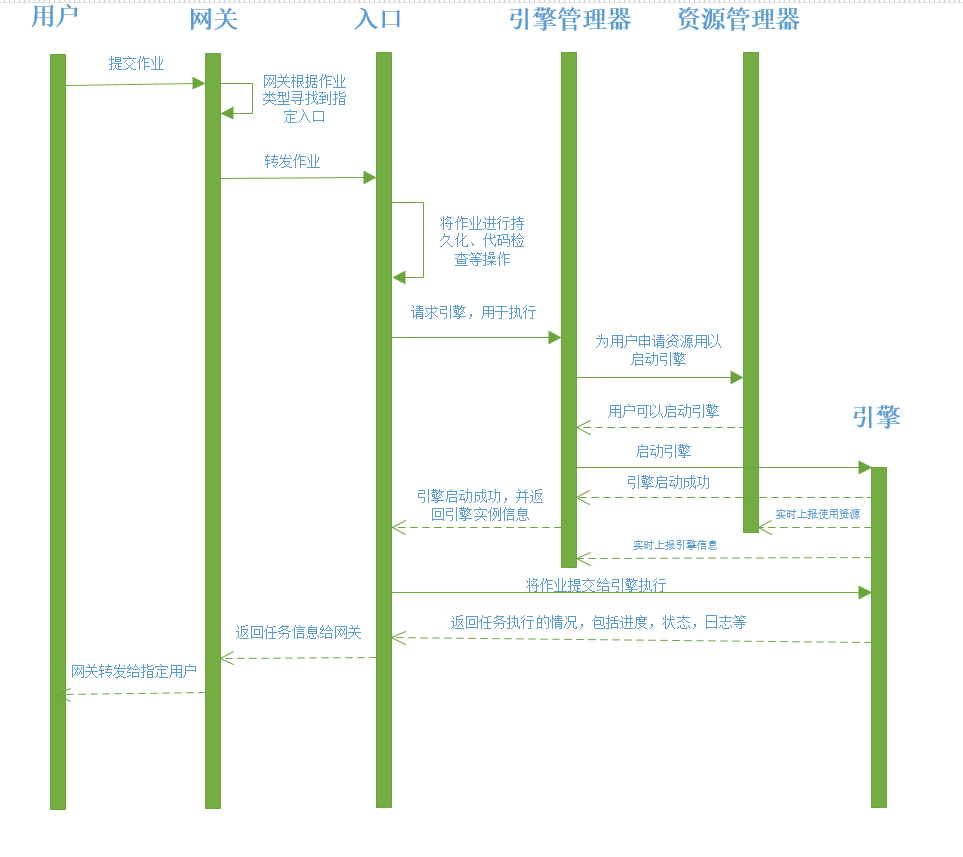
The user of the upper system submits a SQL, which passes through the Gateway first, and the Gateway is responsible for parsing the user request and routing it to the appropriate unified entrance Entrance
Entrance will first find out whether there is any Spark engine service available for the user of the system, and if so, it will directly submit the request to the Spark engine service
There is no available Spark engine service, start to discover the function through Eureka's service registration, get a list of all engine managers, and obtain the actual load of the engine manager in real time by requesting RM
Entrance got the engine manager with the lowest load and started asking the engine manager to start a Spark engine service
When the engine manager receives the request, it starts to ask the user under the RM system whether they can start the new engine
If it can be started, start requesting resources and lock; otherwise, an exception of startup failure is returned to Entrance
The resource is successfully locked, and the new spark engine service is started; after the startup is successful, the new spark engine is returned to Entrance
After Entrance got the new engine, it began to request SQL execution from the new engine
Spark's new engine receives SQL requests, starts submitting SQL to Yarn for execution, and pushes logs, progress and status to Entrance in real time
Entrance pushes the obtained logs, progress and status to Gateway in real time
Gateway pushes back logs, progress and status to the front end
Once the SQL execution is successful, Engine actively pushes the result set to Entrance, and Entrance informs the front end to get the result.
For the design plan under abnormal Entrance/EngineManager/Engine, please refer to UJES Architecture Design Document