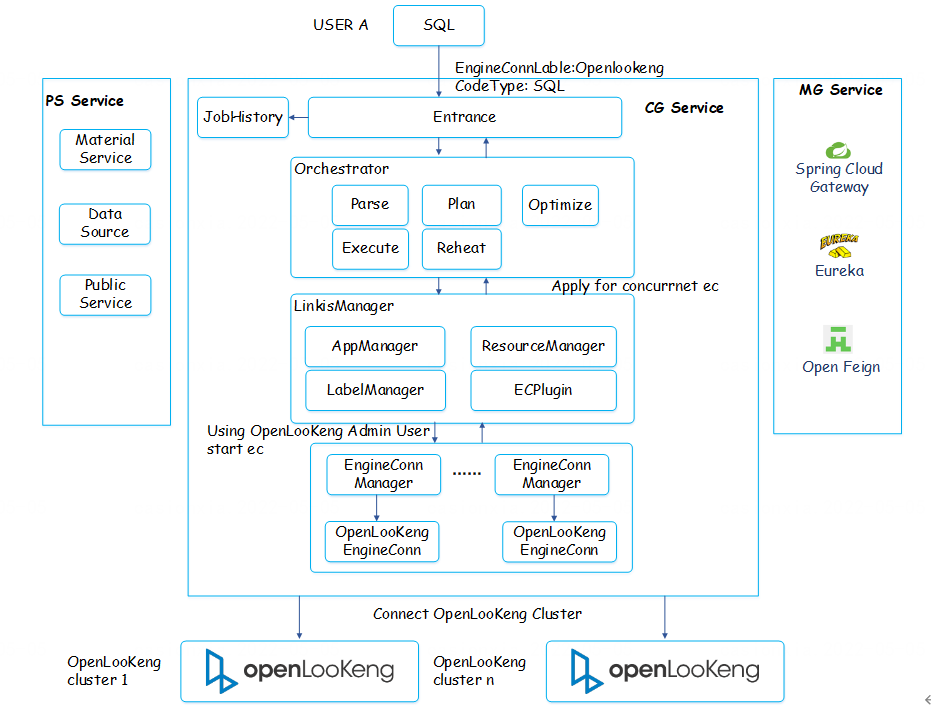
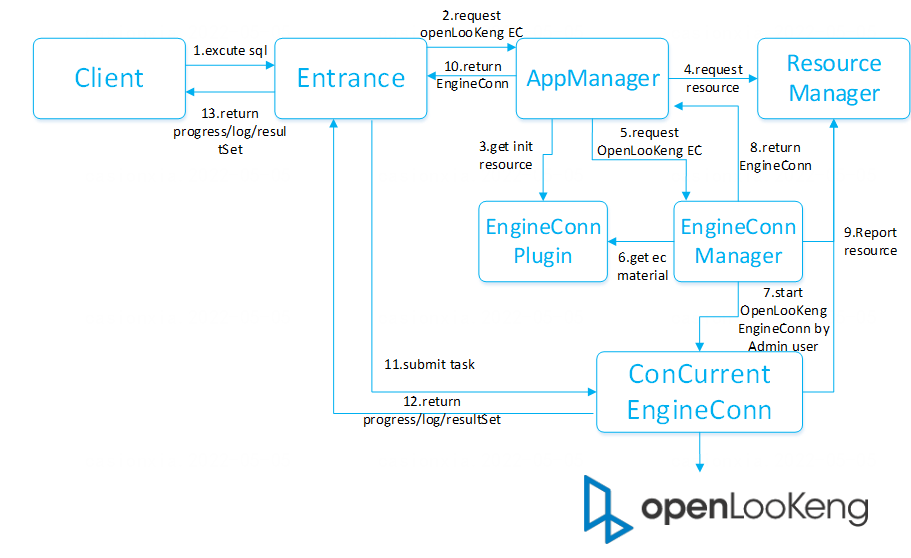
Linkis deployment instructions and precautions
1. Precautions for preparation
1.1 linux server
Hardware requirements
Install nearly 10 linkis microservices. The default configuration of each microservice is to start the jvm-Xmx memory size of 512M (if the memory is not enough, you can try to reduce it to 256/128M, and you can also increase it if the memory is sufficient)
Software Requirements
basic software environment
Use the following command to check whether the corresponding software has been installed, if not, please install it first
command -v java
command -v yum
command -v mysql
command -v telnet
command -v tar
command -v sed
1.2 Add deployment user
Deployment user: the startup user of the linkis core process, and this user will be granted administrator privileges by default, and the corresponding administrator login password will be generated during the deployment process, which is located in the conf/linkis-mg-gateway.properties file
linkis supports specifying the user who submits and executes. The main process service of linkis will switch to the corresponding execution user through sudo -u ${linkis-user}, and execute the corresponding engine startup command, so the process user of the engine process linkis-engine is the execution owner user belonging to the task
Take hadoop user as an example:
First check whether there is already a hadoop user in the system. If it already exists, you can directly authorize it; if not, create a user first, and then authorize.
Check if a hadoop user already exists
$ id hadoop
uid=2001(hadoop) gid=2001(hadoop) groups=2001(hadoop)
If it does not exist, you need to create a hadoop user and join the hadoop user group
$ sudo useradd hadoop -g hadoop
$ vi /etc/sudoers
hadoop ALL=(ALL) NOPASSWD: NOPASSWD: ALL
Modify the environment variables of the installation user, vim /home/hadoop/.bash_rc configure the environment variables, the environment variables are as follows:
export JAVA_HOME=/opt/jdk1.8
export HADOOP_HOME=/opt/install/hadoop
export HADOOP_CONF_DIR=/etc/conf/hadoop
export HIVE_HOME=/opt/install/hive
export HIVE_CONF_DIR=/etc/conf/conf
export SPARK_HOME=/opt/install/spark
export SPARK_CONF_DIR=/etc/spark/conf
export PYSPARK_ALLOW_INSECURE_GATEWAY=1
refresh configuration
$ source /home/hadoop/.bash_rc
Check if it works
$ sudo -su hadoop
$ echo $JAVA_HOME
$ echo $HADOOP_HOME
1.3 Installation package preparation
linkis installation package, it is recommended to use version 1.X and above
The versions of 0.X and 1.X are quite different. Before 1.0.3, it was the package name of com.webank.wedatasphere.linkis, and linkis>=1.0.3 was the package name of org.apache.linkis.
Download address: https://linkis.apache.org/download/main/
1.4 Low-level dependency checking
You can execute the corresponding command to see if it is supported
spark/hive/hdfs/python/
$ spark-submit --version //spark tasks will be submitted to YARN for execution through this command
$ python --version
$ hdfs version
$ hive --version
1.5 Resource dependencies
Accessible mysql database resources Database used to store business data of linkis itself
Accessible yarn resource queues The execution of spark/hive/flink engines requires yarn queue resources
Accessible hive matedata database resources (mysql as an example) Required for hive engine execution
Note: If the version of hive spark is quite different from the default version, it is best to re-edit the relevant hive/spark version that linkis depends on for compilation
2. Install
2.1 Unzip the installation package
After uploading the installation package apache-linkis-1.0.3-incubating-bin.tar.gz, decompress the installation package
$ tar -xvf apache-linkis-1.0.3-incubating-bin.tar.gz
$ pwd
/data/Install/1.0.3
The unzipped directory structure is as follows
-rw-r--r-- 1 hadoop hadoop 531847342 Feb 21 10:10 apache-linkis-1.0.3-incubating-bin.tar.gz
drwxrwxr-x 2 hadoop hadoop 4096 Feb 21 10:13 bin //Script to perform environment check and install
drwxrwxr-x 2 hadoop hadoop 4096 Feb 21 10:13 deploy-config // Environment configuration information such as DB that depends on deployment
-rw-r--r-- 1 hadoop hadoop 1707 Jan 22 2020 DISCLAIMER-WIP
-rw-r--r-- 1 hadoop hadoop 66058 Jan 22 2020 LICENSE
drwxrwxr-x 2 hadoop hadoop 16384 Feb 21 10:13 licenses
drwxrwxr-x 7 hadoop hadoop 4096 Feb 21 10:13 linkis-package // The actual package, including lib/service startup script tool/db initialization script/microservice configuration file, etc.
-rw-r--r-- 1 hadoop hadoop 83126 Jan 22 2020 NOTICE
-rw-r--r-- 1 hadoop hadoop 7900 Jan 22 2020 README_CN.md
-rw-r--r-- 1 hadoop hadoop 8184 Jan 22 2020 README.md
vim deploy-config/db.sh
Example:
MYSQL_HOST=xx.xx.xx.xx
MYSQL_PORT=3306
MYSQL_DB=linkis_test
MYSQL_USER=test
MYSQL_PASSWORD=xxxxx
The file is located at deploy-config/linkis-env.sh
Basic directory configuration
Please confirm that the deployment user deployUser has read and write permissions to these configuration directories
deployUser=hadoop
WORKSPACE_USER_ROOT_PATH=file:///tmp/linkis
RESULT_SET_ROOT_PATH=file:///tmp/linkis
HDFS_USER_ROOT_PATH=hdfs:///tmp/linkis
ENGINECONN_ROOT_PATH=/appcom/tmp
Note: Confirm whether the deployment user has read and write permissions for the corresponding file directory
HIVE_META_URL=jdbc:mysql://127.0.0.1:3306/hive_meta_demo?useUnicode=true&characterEncoding=UTF-8
HIVE_META_USER=demo
HIVE_META_PASSWORD=demo123
Yarn's ResourceManager address
YARN_RESTFUL_URL=http://xx.xx.xx.xx:8088
When executing spark tasks, you need to use the ResourceManager of yarn. Linkis does not enable permission verification by default. If password permission verification is enabled for ResourceManager, please modify the linkis_cg_engine_conn_plugin_bml_resources table data after installation and deployment (or see (#todo))
LDAP login authentication
Linkis uses static users and passwords by default. Static users are deployment users. Static passwords will randomly generate a password string during deployment and store them in {InstallPath}/conf/linkis-mg-gateway.properties (>=1.0.3 version).
It is best to configure it through the user's system environment variables (step 1.2 Adding a deployment user has been explained), you can directly comment it out without configuring in the deploy-config/linkis-env.sh configuration file
If the official release package used does not need to be modified, if it is compiled by modifying the Spark/Hive engine version, it needs to be modified.
If spark is not version 2.4.3, you need to modify the parameters:
If hive is not version 2.3.3, you need to modify the parameters:
If configured, it will actually be updated in the {linkisInstallPath}/conf/linkis.properties file after the installation and deployment are performed
jvm memory configuration
The microservice starts the jvm memory configuration, which can be adjusted according to the actual situation of the machine. If the machine memory resources are few, you can try to adjust it to 256/128M
export SERVER_HEAP_SIZE="512M"
Installation directory configuration
linkis will eventually be installed in this directory, if not configured, the default is the same level directory as the current installation package
LINKIS_HOME=/appcom/Install/LinkisInstall
3. Deployment process
3.1 Execute the deployment script
tip: If an error occurs and you are not sure what command to execute to report the error, you can add the -v parameter sh -v bin/install.sh to print the shell script execution process log, which is convenient for locating the problem.
3.2 Possible problems
1.Permission problem mkdir: cannot create directory ‘xxxx’: Permission denied
The prompt for successful execution is as follows:
Congratulations! You have installed Linkis 1.0.3 successfully, please use sh /data/Install/linkis/sbin/linkis-start-all.sh to start it!
Your default account password is [hadoop/5e8e312b4]
3.3 Configuration modification
After the installation is complete, if you need to modify the configuration, you can re-execute the installation, or modify the corresponding ${InstallPath}/conf/*properties file and restart the corresponding service
3.4 Add mysql driver (>=1.0.3) version
Because of the license, mysql-connector-java is removed from the release package of linkis itself (the family bucket integrated by dss will be included, no need to manually add it), which needs to be added manually.
For details, see [Add mysql driver package](docs/1.0.3/deployment/quick-deploy#-44-Add mysql driver package)
3.5 Start the service
sh sbin/linkis-start-all.sh
3.6 Check whether the service starts normally
Visit the eureka service page (http://eurekaip:20303), version 1.0.x, the following services must be started normally
LINKIS-CG-ENGINECONNMANAGER
LINKIS-CG-ENGINEPLUGIN
LINKIS-CG-ENTRANCE
LINKIS-CG-LINKISMANAGER
LINKIS-MG-EUREKA
LINKIS-MG-GATEWAY
LINKIS-PS-CS
LINKIS-PS-PUBLICSERVICE
If any services are not started, you can view detailed exception logs in the corresponding log/${service name}.log file.
4. Install the web frontend
Mainly perform YARN related configuration
Download the front-end installation package and unzip it
tar -xvf apache-linkis-1.0.3-incubating-web-bin.tar.gz
Modify configuration config.sh
linkis_port="8088"
linkis_url="http://localhost:9020"
Perform front-end deployment
After installation, the nginx configuration file of linkis defaults to /etc/nginx/conf.d/linkis.conf
nginx log files are in /var/log/nginx/access.log and /var/log/nginx/error.log
server {
listen 8188;# access port
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location /linkis/visualis {
root /appcom/Install/linkis-web/linkis/visualis; # static file directory
autoindex on;
}
location / {
root /appcom/Install/linkis-web/dist; # static file directory
index index.html index.html;
}
location /ws {
proxy_pass http://localhost:9020;#Address of backend Linkis
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection upgrade;
}
location /api {
proxy_pass http://localhost:9020; #Address of backend Linkis
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header x_real_ipP $remote_addr;
proxy_set_header remote_addr $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_http_version 1.1;
proxy_connect_timeout 4s;
proxy_read_timeout 600s;
proxy_send_timeout 12s;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection upgrade;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
If you need to modify the port or static resource directory, etc., please modify the /etc/nginx/conf.d/linkis.conf file and execute the sudo nginx -s reload command
Log in to the web terminal to view information
http://xx.xx.xx.xx:8188/#/login
Username/Password (check in {InstallPath}/conf/linkis-mg-gateway.properties)
wds.linkis.admin.user=
wds.linkis.admin.password=
After logging in, check whether the yarn queue resources can be displayed normally (if you want to use the spark/hive/flink engine)
Normally as shown below:
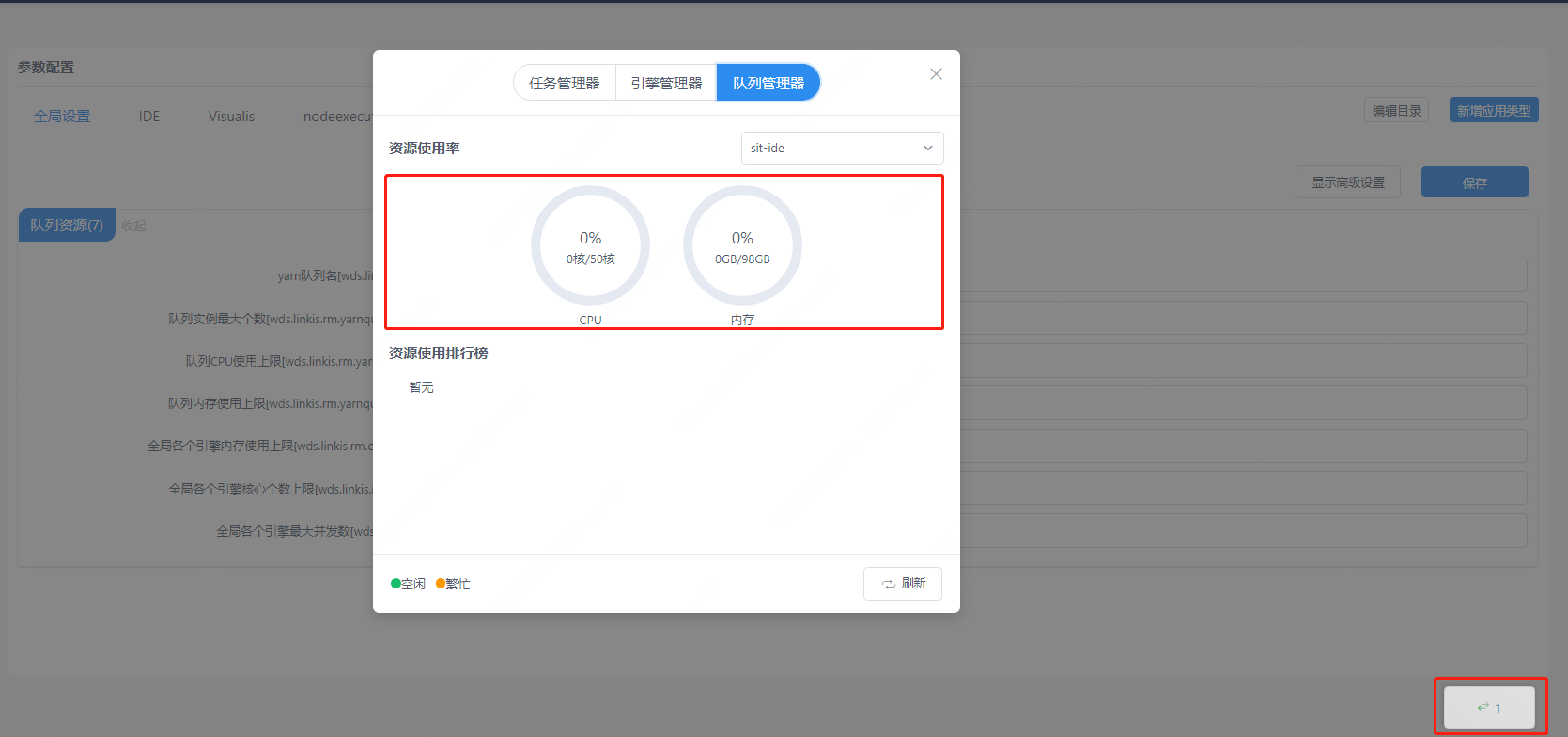
If it cannot be displayed:
Database table linkis_cg_rm_external_resource_provider
Insert yarn data information
INSERT INTO `linkis_cg_rm_external_resource_provider`
(`resource_type`, `name`, `labels`, `config`) VALUES
('Yarn', 'default', NULL,
'{\r\n"rmWebAddress": "http://xx.xx.xx.xx:8088",\r\n"hadoopVersion": "2.7.2",\r\n"authorEnable":false, \r\n"user":"hadoop",\r\n"pwd":"1234
56"\r\n}'
);
config field properties
"rmWebAddress": "http://xx.xx.xx.xx:8088",
"hadoopVersion": "2.7.2",
"authorEnable":true,
"user":"user",
"pwd":"pwd"
After the update, because the cache is used in the program, if you want to take effect immediately, you need to restart the linkis-cg-linkismanager service
sh sbin/linkis-daemon.sh restart cg-linkismanager
2 Check whether the yarn queue is correct
Exception message: desc: queue ide is not exists in YARN.
The configuration yarn queue does not exist and needs to be adjusted
Modification method: linkis management console/parameter configuration > global settings > yarn queue name [wds.linkis.rm.yarnqueue] Modify a usable yarn queue
Available yarn queues can be viewed at rmWebAddress:http://xx.xx.xx.xx:8088
5. Check if the engine material resource is uploaded successfully
select * from linkis_cg_engine_conn_plugin_bml_resources
normal as follows

Check whether the material record of the engine exists (if there is an update, check whether the update time is correct).
If it does not exist or is not updated, first try to manually refresh the material resource (for details, see [Engine Material Resource Refresh](docs/latest/deployment/install-engineconn#23-Engine Refresh)). Check the log/linkis-cg-engineplugin.log log to check the specific reasons for the failure of the material. In many cases, it may be caused by the lack of permissions in the hdfs directory. Check whether the gateway address configuration is correct conf/linkis.properties:wds.linkis.gateway.url
The material resources of the engine are uploaded to the hdfs directory by default as /apps-data/${deployUser}/bml
hdfs dfs -ls /apps-data/hadoop/bml
hdfs dfs -mkdir /apps-data
hdfs dfs -chown hadoop:hadoop/apps-data
##Verify basic functions
#The version number of the engineType of the engine must match the actual one
sh bin/linkis-cli -submitUser hadoop -engineType shell-1 -codeType shell -code "whoami"
sh bin/linkis-cli -submitUser hadoop -engineType hive-2.3.3 -codeType hql -code "show tables"
sh bin/linkis-cli -submitUser hadoop -engineType spark-2.4.3 -codeType sql -code "show tables"
sh bin/linkis-cli -submitUser hadoop -engineType python-python2 -codeType python -code 'print("hello, world!")'
View supported versions of each engine
Method 1: View the directory packaged by the engine
$ tree linkis-package/lib/linkis-engineconn-plugins/ -L 3
linkis-package/lib/linkis-engineconn-plugins/
├── hive
│ ├── dist
│ │ └── v2.3.3 #version is 2.3.3 engineType is hive-2.3.3
│ └── plugin
│ └── 2.3.3
├── python
│ ├── dist
│ │ └── vpython2
│ └── plugin
│ └── python2 #version is python2 engineType is python-python2
├── shell
│ ├── dist
│ │ └── v1
│ └── plugin
│ └── 1
└── spark
├── dist
│ └── v2.4.3
└── plugin
└── 2.4.3
Method 2: View the database table of linkis
select * from linkis_cg_engine_conn_plugin_bml_resources
6. Troubleshooting installation and deployment common problems
6.1 Version compatibility issues
The engine supported by linkis by default, for compatibility with dss, you can view this document https://github.com/apache/linkis/blob/master/README.md
6.2 How to locate the server exception log
Linkis has many microservices. If you are unfamiliar with the system, sometimes you cannot locate the specific module that has an exception. You can search through the global log.
tail -f log/* |grep -5n exception (or tail -f log/* |grep -5n ERROR)
less log/* |grep -5n exception (or less log/* |grep -5n ERROR)
6.3 Execution of abnormal troubleshooting of engine tasks
step1: Find the startup deployment directory of the engine
Method 1: If it is displayed in the execution log, you can view it on the management console as shown below:
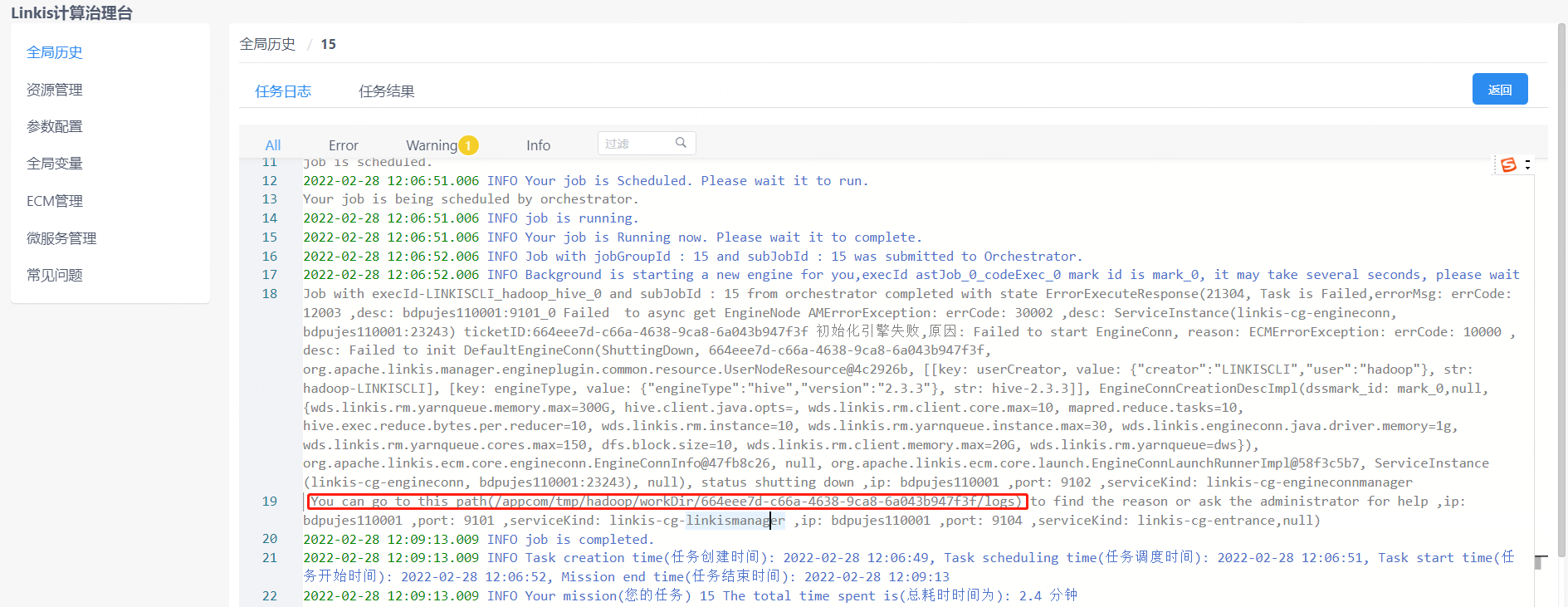 Method 2: If it is not found in method 1, you can find the parameter of
Method 2: If it is not found in method 1, you can find the parameter of wds.linkis.engineconn.root.dir configured in conf/linkis-cg-engineconnmanager.properties, which is the directory where the engine is started and deployed. The user of the execution engine is isolated (taskId). If you do not know the taskid, you can select it after sorting by time. ll -rt /appcom/tmp/${executing user}/workDir
cd /appcom/tmp/${executing user}/workDir/${taskId}
# The directory is roughly as follows
conf -> /appcom/tmp/engineConnPublickDir/6a09d5fb-81dd-41af-a58b-9cb5d5d81b5a/v000002/conf #engine configuration file
engineConnExec.sh #Generated engine startup script
lib -> /appcom/tmp/engineConnPublickDir/45bf0e6b-0fa5-47da-9532-c2a9f3ec764d/v000003/lib #Engine dependent packages
logs #Engine startup and execution related logs
step2: View the log of the engine
less logs/stdout
step3: try to execute the script manually (if needed)
Debugging can be done by trying to execute the script manually
sh engineConnExec.sh
6.4 Notes on CDH adaptation version
CDH itself is not an official standard hive/spark package. When adapting, it is best to modify the hive/spark version dependencies in the source code of linkis to recompile and deploy.
For details, please refer to the CDH adaptation blog post
[Linkis1.0 - Installation and Stepping in the CDH5 Environment]
[DSS1.0.0+Linkis1.0.2——Trial record in CDH5 environment]
[DSS1.0.0 and Linkis1.0.2——Summary of JDBC engine related issues]
[DSS1.0.0 and Linkis1.0.2——Summary of Flink engine related issues]
6.6 Debugging of Http interface
Method 1 can open the [Login-Free Mode Guide] (docs/latest/api/login-api#2 Login-Free Configuration)
Method 2: Add a static Token to the http request header
Token-User:hadoop
Token-Code: BML-AUTH
6.7 Troubleshooting process for abnormal problems
First, follow the above steps to check whether the service/environment, etc. are all started normally
Troubleshoot basic problems according to some of the scenarios listed above
QA documentation Find out if there is a solution, link: https://docs.qq.com/doc/DSGZhdnpMV3lTUUxq
See if you can find a solution by searching the content in the issue
 Through the official website document search, for some problems, you can search for keywords through the official website, such as searching for "deployment". (If 404 appears, please refresh your browser)
Through the official website document search, for some problems, you can search for keywords through the official website, such as searching for "deployment". (If 404 appears, please refresh your browser)
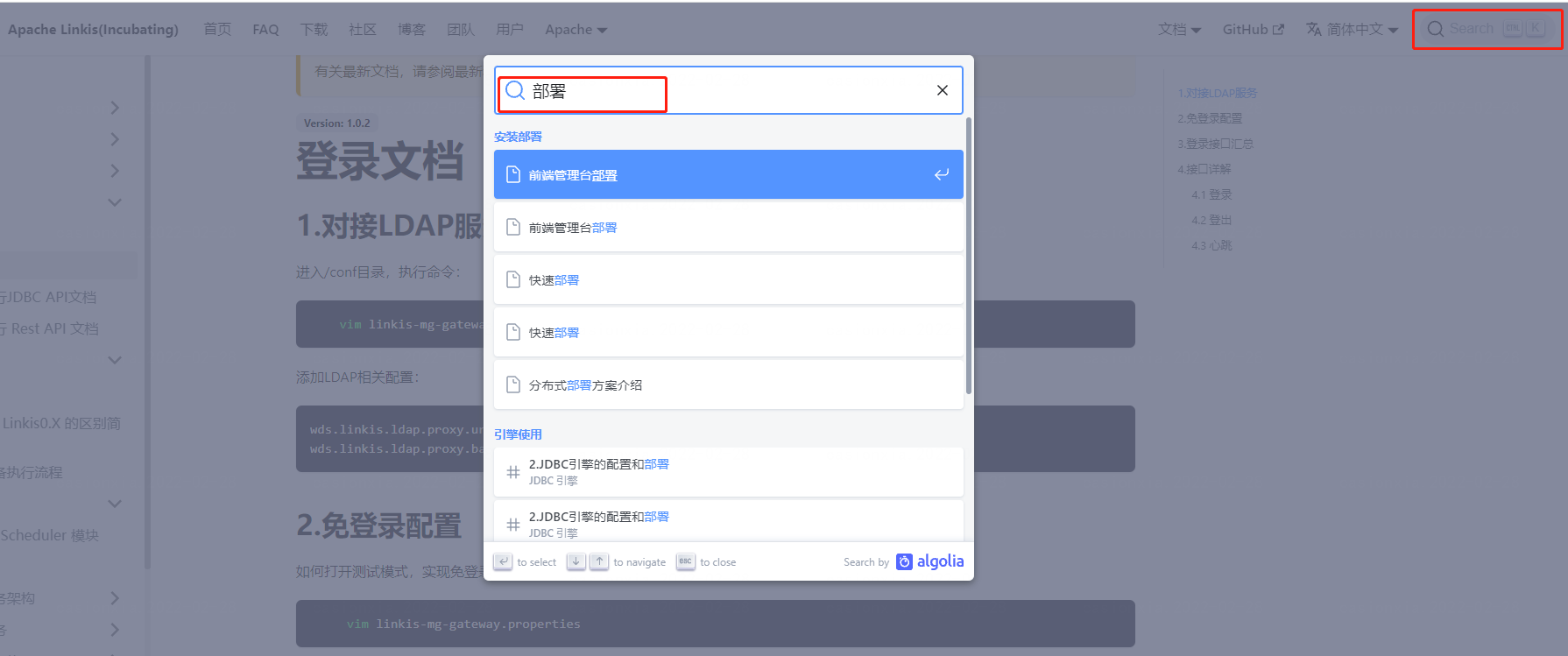
Linkis official website documents are constantly improving, you can view/keyword search related documents on this official website.
Related blog post links